

{kind=link}
Ars Technica
Les choses bougent à la vitesse de l’éclair dans AI Land. Vendredi, un développeur de logiciels nommé Georgi Gerganov a créé un outil appelé “llama.cpp” qui peut exécuter le nouveau modèle de grand langage d’IA de classe GPT-3 de Meta, LLaMA, localement sur un ordinateur portable Mac. Peu de temps après, les gens ont également compris comment exécuter LLaMA sous Windows. Ensuite, quelqu’un l’a montré en cours d’exécution sur un téléphone Pixel 6, puis est venu un Raspberry Pi (bien que fonctionnant très lentement).
Si cela continue, nous pourrions envisager un concurrent ChatGPT de poche avant de le savoir.
Mais revenons en arrière une minute, car nous n’en sommes pas encore là. (Du moins pas aujourd’hui, comme littéralement aujourd’hui, le 13 mars 2023.) Mais ce qui arrivera la semaine prochaine, personne ne le sait.
Depuis le lancement de ChatGPT, certaines personnes ont été frustrées par les limites intégrées du modèle d’IA qui l’empêchent de discuter de sujets qu’OpenAI a jugés sensibles. Ainsi a commencé le rêve – dans certains milieux – d’un grand modèle de langage open source (LLM) que n’importe qui pourrait exécuter localement sans censure et sans payer de frais d’API à OpenAI.
Des solutions open source existent (telles que GPT-J), mais elles nécessitent beaucoup de RAM GPU et d’espace de stockage. D’autres alternatives open source ne pourraient pas se vanter de performances de niveau GPT-3 sur du matériel grand public facilement disponible.
Entrez LLaMA, un LLM disponible dans des tailles de paramètres allant de 7B à 65B (c’est-à-dire “B” comme dans “milliards de paramètres”, qui sont des nombres à virgule flottante stockés dans des matrices qui représentent ce que le modèle “sait”). LLaMA a fait une affirmation captivante : que ses modèles de plus petite taille pourraient correspondre au GPT-3 d’OpenAI, le modèle fondamental qui alimente ChatGPT, dans la qualité et la vitesse de sa sortie. Il n’y avait qu’un seul problème – Meta a publié le code open source LLaMA, mais il a retenu les “poids” (les “connaissances” formées stockées dans un réseau de neurones) pour les chercheurs qualifiés uniquement.
Publicité
Voler à la vitesse de LLaMA
Les restrictions de Meta sur LLaMA n’ont pas duré longtemps, car le 2 mars, quelqu’un a divulgué les poids LLaMA sur BitTorrent. Depuis lors, il y a eu une explosion de développement autour de LLaMA. Le chercheur indépendant en intelligence artificielle Simon Willison a comparé cette situation à la sortie de Stable Diffusion, un modèle de synthèse d’images open source lancé en août dernier. Voici ce qu’il a écrit dans un article sur son blog :
J’ai l’impression que ce moment de Stable Diffusion en août a déclenché toute une nouvelle vague d’intérêt pour l’IA générative, qui a ensuite été poussée à l’extrême par la sortie de ChatGPT fin novembre.
Ce moment de diffusion stable se reproduit en ce moment, pour les grands modèles de langage, la technologie derrière ChatGPT elle-même. Ce matin, j’ai exécuté pour la première fois un modèle de langage de classe GPT-3 sur mon ordinateur portable personnel !
Les trucs d’IA étaient déjà bizarres. C’est sur le point de devenir beaucoup plus bizarre.
En règle générale, l’exécution de GPT-3 nécessite plusieurs GPU A100 de classe centre de données (de plus, les poids de GPT-3 ne sont pas publics), mais LLaMA a fait des vagues car il pouvait fonctionner sur un seul GPU grand public costaud. Et maintenant, avec des optimisations qui réduisent la taille du modèle à l’aide d’une technique appelée quantification, LLaMA peut fonctionner sur un Mac M1 ou un GPU grand public Nvidia moindre.
Les choses évoluent si vite qu’il est parfois difficile de suivre les derniers développements. (En ce qui concerne le rythme de progression de l’IA, un collègue journaliste de l’IA a déclaré à Ars : “C’est comme ces vidéos de chiens où vous renversez une caisse de balles de tennis dessus. [They] ne sais pas par où chasser en premier et se perdre dans la confusion.”)
Par exemple, voici une liste d’événements notables liés à LLaMA basée sur une chronologie que Willison a présentée dans un commentaire de Hacker News :
- 24 février 2023 : Meta AI annonce LLaMA.
- 2 mars 2023 : Quelqu’un divulgue les modèles LLaMA via BitTorrent.
- 10 mars 2023 : Georgi Gerganov crée llama.cpp, qui peut fonctionner sur un Mac M1.
- 11 mars 2023 : Artem Andreenko exécute LLaMA 7B (lentement) sur un Raspberry Pi 4, 4 Go de RAM, 10 sec/token.
- 12 mars 2023 : LLaMA 7B exécuté sur NPX, un outil d’exécution node.js.
- 13 mars 2023 : Quelqu’un fait fonctionner llama.cpp sur un téléphone Pixel 6, également très lentement.
- 13 mars 2023, 2023 : Stanford lance Alpaca 7B, une version optimisée pour les instructions de LLaMA 7B qui « se comporte de la même manière que le « text-davinci-003 » d’OpenAI mais fonctionne sur un matériel beaucoup moins puissant.
Publicité
Après avoir obtenu nous-mêmes les poids LLaMA, nous avons suivi les instructions de Willison et avons fait fonctionner la version des paramètres 7B sur un Macbook Air M1, et elle fonctionne à une vitesse raisonnable. Vous l’appelez comme un script sur la ligne de commande avec une invite, et LLaMA fait de son mieux pour le terminer de manière raisonnable.
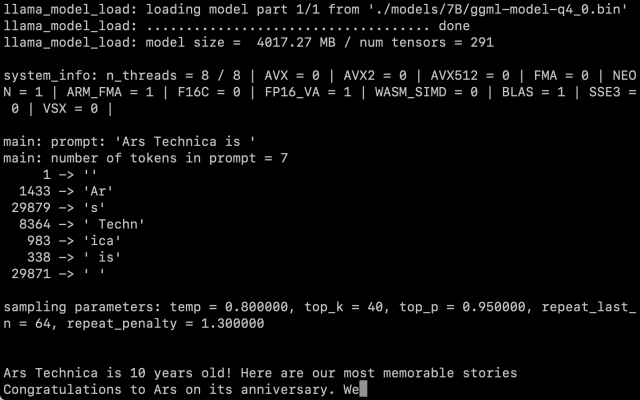 Agrandir / Une capture d’écran de LLaMA 7B en action sur un MacBook Air exécutant llama.cpp.
Agrandir / Une capture d’écran de LLaMA 7B en action sur un MacBook Air exécutant llama.cpp.
Benj Edwards / Ars Technica
Reste la question de savoir dans quelle mesure la quantification affecte la qualité de la sortie. Lors de nos tests, LLaMA 7B réduit à la quantification 4 bits était très impressionnant pour fonctionner sur un MacBook Air, mais toujours pas à la hauteur de ce que vous pourriez attendre de ChatGPT. Il est tout à fait possible que de meilleures techniques d’incitation génèrent de meilleurs résultats.
De plus, les optimisations et les ajustements sont rapides lorsque tout le monde a la main sur le code et les poids, même si LLaMA est toujours aux prises avec des conditions d’utilisation assez restrictives. La sortie d’Alpaca aujourd’hui par Stanford prouve qu’un réglage fin (entraînement supplémentaire avec un objectif spécifique en tête) peut améliorer les performances, et il est encore tôt après la sortie de LLaMA.
Au moment d’écrire ces lignes, l’exécution de LLaMA sur un Mac reste un exercice assez technique. Vous devez installer Python et Xcode et être familiarisé avec le travail en ligne de commande. Willison a de bonnes instructions étape par étape pour tous ceux qui souhaitent l’essayer. Mais cela pourrait bientôt changer à mesure que les développeurs continuent de coder.
Quant aux implications d’avoir cette technologie dans la nature, personne ne le sait encore. Alors que certains s’inquiètent de l’impact de l’IA en tant qu’outil de spam et de désinformation, Willison déclare : “Cela ne sera pas inventé, donc je pense que notre priorité devrait être de trouver les moyens les plus constructifs possibles de l’utiliser.”
À l’heure actuelle, notre seule garantie est que les choses vont changer rapidement.