

{kind=link}
Agrandir / Le service Enhance Speech d’Adobe peut supprimer le bruit de fond de certains enregistrements vocaux.
Adobe
Récemment, Adobe a publié un outil de traitement audio gratuit alimenté par l’IA qui peut améliorer certains enregistrements vocaux de mauvaise qualité en supprimant le bruit de fond et en rendant le son de la voix plus fort. Lorsqu’il fonctionne, le résultat ressemble à un enregistrement réalisé dans une cabine de son professionnelle avec un microphone de haute qualité.
Le nouvel outil, appelé Enhance Speech, est né dans le cadre d’un projet de recherche sur l’IA appelé Project Shasta. Récemment, Adobe a renommé Project Shasta en Adobe Podcast.
L’utilisation d’Enhancer Speech est gratuite, mais nécessite la création d’un compte Adobe et fonctionne mieux avec un navigateur Web de bureau. Une fois enregistrés, les utilisateurs peuvent télécharger un fichier MP3 ou WAV d’une durée maximale d’une heure ou d’une taille de 1 Go. Après plusieurs minutes, vous pouvez écouter le résultat dans votre navigateur ou télécharger l’audio nettoyé résultant.
Lors de nos tests avec le service, Enhance Speech fonctionnait mieux avec un son contenant une voix sans diaphonie ni bruit excessif. Par exemple, nous avons enregistré l’audio à partir du microphone intégré d’un iMac d’une personne se tenant à 10 pieds, y compris le bruit du ventilateur à proximité, et l’audio résultant (une fois traité par Enhance Speech) sonnait comme s’il avait été enregistré de près dans un environnement sans bruit. studio avec un microphone professionnel.
Publicité
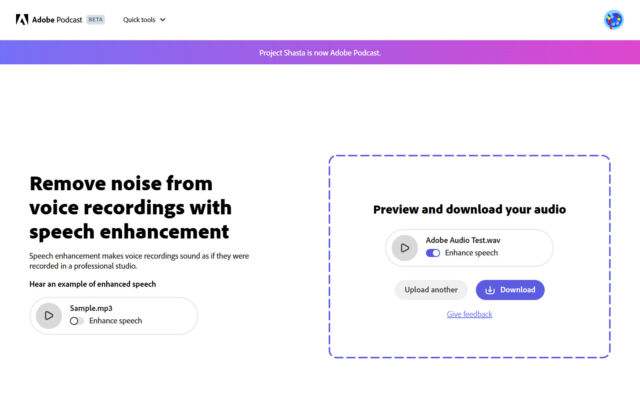 Agrandir / Enhance Speech permet de télécharger des fichiers MP3 ou WAV d’une taille maximale de 1 Go ou d’une durée d’une heure.
Agrandir / Enhance Speech permet de télécharger des fichiers MP3 ou WAV d’une taille maximale de 1 Go ou d’une durée d’une heure.
Adobe
Comment ça marche? Adobe n’a fourni aucun détail, mais nous soupçonnons que la société a formé un modèle d’apprentissage en profondeur sur de nombreuses heures (peut-être des milliers) d’audio propre et bruyant. Le modèle pourrait alors “apprendre” à repérer les fréquences de la voix humaine et à synthétiser un fac-similé qui correspond exactement à la source. Il s’agit de spéculations jusqu’à ce qu’Adobe fournisse plus de détails techniques, et nous avons contacté la société pour obtenir des commentaires.
Sur ce point, certains commentateurs de Hacker News ont signalé des résultats hallucinants – une sortie inattendue comme des voix fantômes où l’IA interprète mal l’audio d’entrée – à partir d’un son extrêmement bruyant (comme un discours enregistré à côté d’une cascade) ou de sources non anglophones, ce qui suggère que Enhance Speech fait plus qu’une simple technique conventionnelle de réduction du bruit.
Enhance Speech n’est pas le premier outil à fournir ce type de capacité de réduction du bruit alimentée par l’IA. Un package open source appelé mayavoz et un service commercial appelé Audo Studio font quelque chose de similaire, par exemple.
Il convient de noter que Enhance Speech fait partie d’un groupe plus large d’outils de podcasting basés sur l’IA d’Adobe, y compris un outil Mic Check (actuellement également disponible gratuitement) et un outil d’édition audio basé sur la transcription qui fait toujours l’objet d’une invitation. seul test bêta.