

{kind=link}
Agrandir / Une image générée par l’IA de notes de musique explosant à partir d’un écran d’ordinateur.
Ars Technica
Jeudi, deux passionnés de technologie ont publié Riffusion, un modèle d’IA qui génère de la musique à partir d’invites de texte en créant une représentation visuelle du son et en la convertissant en audio pour la lecture. Il utilise une version affinée du modèle de synthèse d’image Stable Diffusion 1.5, appliquant la diffusion latente visuelle au traitement du son d’une manière nouvelle.
Créé en tant que projet de loisir par Seth Forsgren et Hayk Martiros, Riffusion fonctionne en générant des sonogrammes, qui stockent l’audio dans une image bidimensionnelle. Dans un sonagramme, l’axe X représente le temps (l’ordre dans lequel les fréquences sont jouées, de gauche à droite) et l’axe Y représente la fréquence des sons. Pendant ce temps, la couleur de chaque pixel de l’image représente l’amplitude du son à ce moment donné.
L’échographie étant un type d’image, Stable Diffusion peut la traiter. Forsgren et Martiros ont formé un modèle de diffusion stable personnalisé avec des exemples de sonogrammes liés à des descriptions des sons ou des genres musicaux qu’ils représentaient. Grâce à ces connaissances, Riffusion peut générer de la nouvelle musique à la volée en fonction d’invites textuelles décrivant le type de musique ou de son que vous souhaitez entendre, comme “jazz”, “rock” ou même taper sur un clavier.
Après avoir généré l’image du sonagramme, Riffusion utilise Torchaudio pour changer le sonagramme en son, en le lisant en tant qu’audio.
Publicité
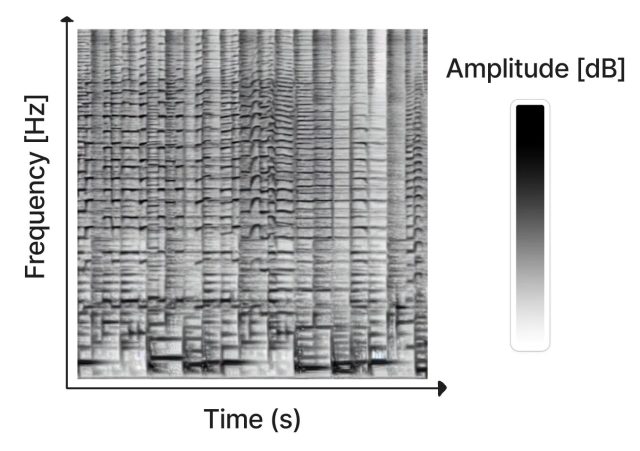 Agrandir / Un sonagramme représente le temps, la fréquence et l’amplitude dans une image bidimensionnelle.
Agrandir / Un sonagramme représente le temps, la fréquence et l’amplitude dans une image bidimensionnelle.
“Il s’agit du modèle de diffusion stable v1.5 sans modifications, juste affiné sur des images de spectrogrammes associées à du texte”, écrivent les créateurs de Riffusion sur sa page d’explication. “Il peut générer des variations infinies d’une invite en faisant varier la graine. Toutes les mêmes interfaces utilisateur Web et techniques comme img2img, inpainting, les invites négatives et l’interpolation fonctionnent hors de la boîte.”
Les visiteurs du site Web de Riffusion peuvent expérimenter le modèle d’IA grâce à une application Web interactive qui génère des sonogrammes interpolés (en douceur assemblés pour une lecture ininterrompue) en temps réel tout en visualisant le spectrogramme en continu sur le côté gauche de la page.
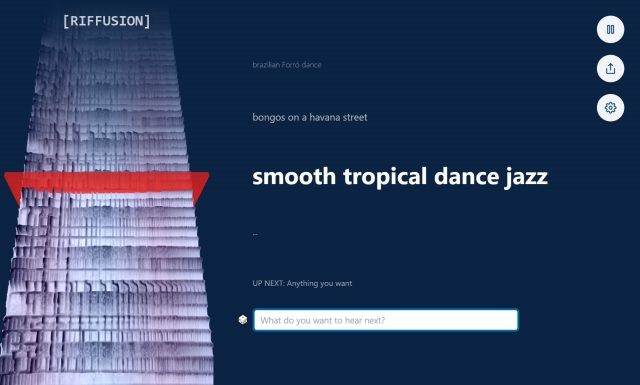 Agrandir / Une capture d’écran du site Web Riffusion, qui vous permet de taper des invites et d’entendre les sonogrammes résultants.
Agrandir / Une capture d’écran du site Web Riffusion, qui vous permet de taper des invites et d’entendre les sonogrammes résultants.
Il peut aussi fusionner les styles. Par exemple, taper “smooth tropical dance jazz” apporte des éléments de genres différents pour un résultat inédit, encourageant l’expérimentation en mélangeant les styles.
Bien sûr, Riffusion n’est pas le premier générateur de musique alimenté par l’IA. Plus tôt cette année, Harmonai a lancé Dance Diffusion, un modèle de musique générative alimenté par l’IA. Le Jukebox d’OpenAI, annoncé en 2020, génère également de la nouvelle musique avec un réseau de neurones. Et des sites Web comme Soundraw créent de la musique à la volée.
Comparé à ces efforts de musique AI plus rationalisés, Riffusion ressemble plus au projet de passe-temps qu’il est. La musique qu’il génère va de l’intéressant à l’inintelligible, mais il reste une application notable de la technologie de diffusion latente qui manipule l’audio dans un espace visuel.
Le point de contrôle et le code du modèle Riffusion sont disponibles sur GitHub.