

{kind=link}
Lors de son Cloud Data Summit, Google a annoncé aujourd’hui le lancement en avant-première de BigLake, un nouveau moteur de stockage de lac de données qui permet aux entreprises d’analyser plus facilement les données dans leurs entrepôts de données et leurs lacs de données.
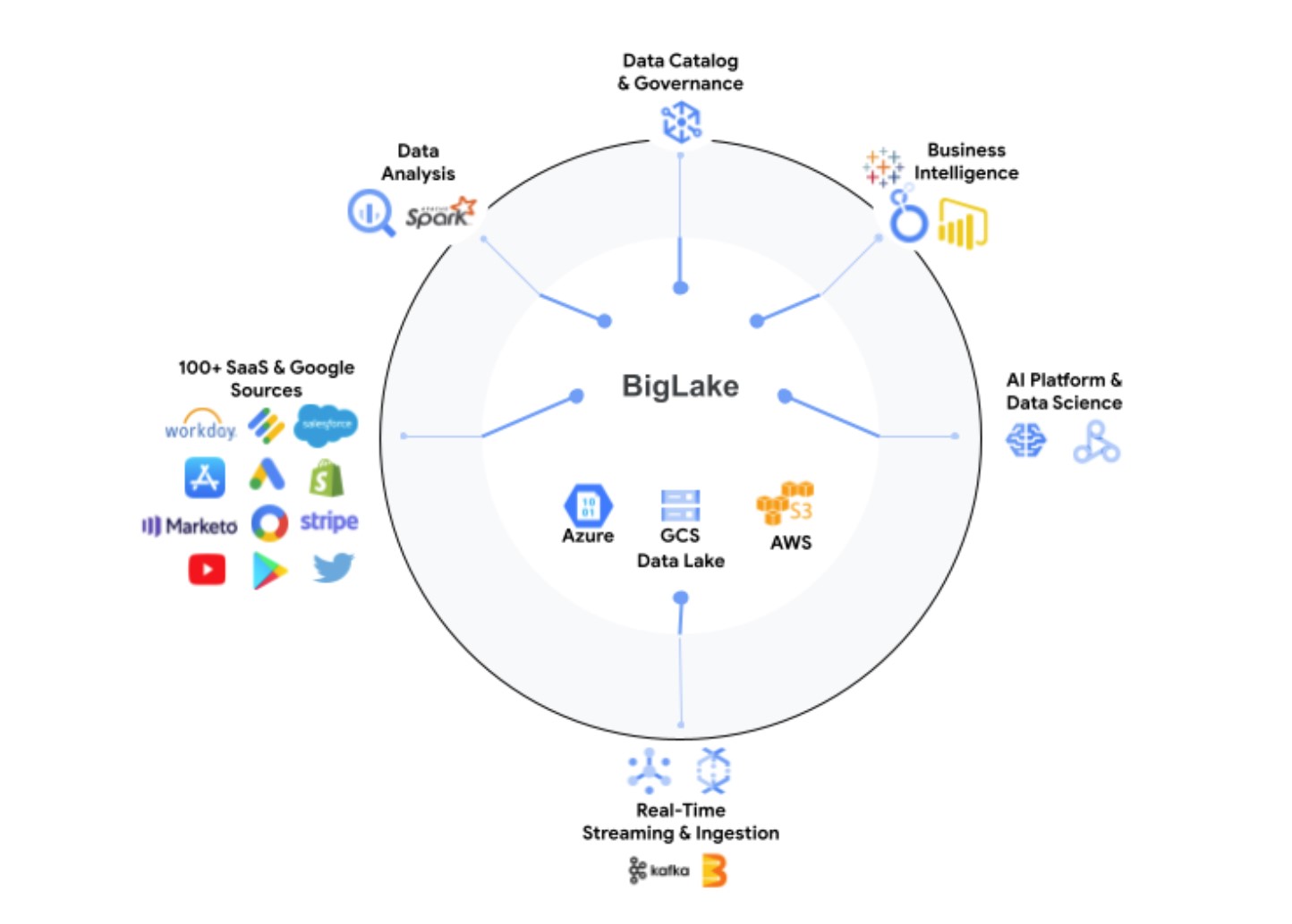
L’idée ici, à la base, est de prendre l’expérience de Google dans l’exécution et la gestion de son entrepôt de données BigQuery et de l’étendre aux lacs de données sur Google Cloud Storage, en combinant le meilleur des lacs de données et des entrepôts en un seul service qui fait abstraction du stockage sous-jacent. formats et systèmes.
Ces données, il convient de le noter, pourraient se trouver dans BigQuery ou vivre également sur AWS S3 et Azure Data Lake Storage Gen2. Grâce à BigLake, les développeurs auront accès à un moteur de stockage uniforme et la possibilité d’interroger les magasins de données sous-jacents via un système unique sans avoir besoin de déplacer ou de dupliquer des données.
“La gestion des données dans des lacs et des entrepôts disparates crée des silos et augmente les risques et les coûts, en particulier lorsque les données doivent être déplacées », explique Gerrit Kazmaier, vice-président et directeur général des bases de données, de l’analyse des données et de la veille économique chez Google Cloud., note dans l’annonce d’aujourd’hui. “BigLake permet aux entreprises d’unifier leurs entrepôts de données et leurs lacs pour analyser les données sans se soucier du format ou du système de stockage sous-jacent, ce qui élimine le besoin de dupliquer ou de déplacer des données à partir d’une source et réduit les coûts et les inefficacités.
Crédits image : Google
À l’aide de balises de stratégie, BigLake permet aux administrateurs de configurer leurs politiques de sécurité au niveau de la table, de la ligne et de la colonne. Cela inclut les données stockées dans Google Cloud Storage, ainsi que les deux systèmes tiers pris en charge, où BigQuery Omni, le service d’analyse multi-cloud de Google, active ces contrôles de sécurité. Ces contrôles de sécurité garantissent également que seules les bonnes données circulent dans des outils tels que Spark, Presto, Trino et TensorFlow. Le service s’intègre également à l’outil Dataplex de Google pour fournir des fonctionnalités supplémentaires de gestion des données.
Google note que BigLake fournira des contrôles d’accès précis et que son API couvrira Google Cloud, ainsi que des formats de fichiers tels que Apache Parquet ouvert orienté colonne et des moteurs de traitement open source comme Apache Spark.
Crédits image : Google
“Le volume de données précieuses que les organisations doivent gérer et analyser augmente à un rythme incroyable”, expliquent l’ingénieur logiciel Google Cloud Justin Levandoski et le chef de produit Gaurav Saxena dans l’annonce d’aujourd’hui. « Ces données sont de plus en plus distribuées sur de nombreux sites, notamment des entrepôts de données, des lacs de données et des magasins NoSQL. À mesure que les données d’une organisation deviennent plus complexes et prolifèrent dans des environnements de données disparates, des silos apparaissent, créant des risques et des coûts accrus, en particulier lorsque ces données doivent être déplacées. Nos clients l’ont clairement indiqué; ils ont besoin d’aide.”
En plus de BigLake, Google a également annoncé aujourd’hui que Spanner, sa base de données SQL distribuée dans le monde entier, bénéficiera bientôt d’une nouvelle fonctionnalité appelée “modifier les flux”. Avec ceux-ci, les utilisateurs peuvent facilement suivre en temps réel toutes les modifications apportées à une base de données, qu’il s’agisse d’insertions, de mises à jour ou de suppressions. “Cela garantit que les clients ont toujours accès aux données les plus récentes, car ils peuvent facilement répliquer les modifications de Spanner vers BigQuery pour des analyses en temps réel, déclencher le comportement des applications en aval à l’aide de Pub/Sub ou stocker les modifications dans Google Cloud Storage (GCS) pour la conformité”, explique Kazmaier.
Google Cloud a également apporté aujourd’hui Vertex AI Workbench, un outil de gestion de l’ensemble du cycle de vie d’un projet de science des données, hors version bêta et en disponibilité générale, et a lancé Connected Sheets pour Looker, ainsi que la possibilité d’accéder aux modèles de données Looker dans ses données Outil Studio BI.