

{kind=link}
At some point, every PC enthusiast will want to make an upgrade of some kind. It might be the entire platform, with a new CPU, motherboard, and a set of fancy RAM. Or it might just be a single item, such as a new solid state drive.
But what about when you’re in the market for a new graphics card and prices are still sky high? Just how much better is one of the latest GPUs compared to an architecture that first appeared over four years ago? Well, read on to find out how one person’s upgrade choice all panned out.
What card to get? Choices and decisions
Everybody has different uses for their graphics card — for some, it’ll be purely for entertainment (gaming, watching videos), whereas for others it will be entirely work-based (rendering, video editing, compute workloads). For me, it’s a mixture of them all, with a heavy emphasis on experimenting with rendering techniques, especially ray tracing, and AI.
For the past three years, I’ve been using an MSI GeForce RTX 2080 Super Ventus XS OC for all those duties. Stupid name aside, it’s been a veritable workhorse, chugging away at most things sent its way. However, the card struggles with high resolutions, it’s pretty hopeless at ray tracing, and is really starting to show its age compute-wise.
So when it came to choosing what upgrade to consider, there was one word that dominated the decision: CUDA. For better or worse, Nvidia’s platform of GPU and software is very much the standard when it comes to the compute and rendering. Both AMD and Intel have invested a lot of time and money into developing the likes of ROCm and OneAPI, but none of the software I use offers any support for them.
That meant sticking with Nvidia and then making another choice — Ampere or Ada? Despite being over two years old, something like a GeForce RTX 3080 10GB is still very capable and can be found new in the UK for around £700. The second-hand market is particularly full of them, and at some great prices, too, but it’s just not a route I wanted to consider.
The only Ada model anywhere near that price is, of course, the GeForce RTX 4080 12GB 4070 Ti, with an MSRP of £799 — except they’re not that price. The cheapest models tend to be around £830, which is a small but annoying 4% difference.
| GPU Parameters | RTX 2080 Super | RTX 3080 | RTX 4070 Ti |
| Boost clock (GHz) | 1.815 | 1.710 | 2.610 |
| GPC | TPC Counts | 6 | 24 | 6 | 34 | 5 | 30 |
| SM Count | 48 | 68 | 60 |
| FP32 Cores | 3072 | 8704 | 7680 |
| INT32 Cores | 3072 | 4352 | 3840 |
| Tensor Cores | 384 | 272 | 240 |
| TMUs | 192 | 272 | 240 |
| ROPs | 64 | 96 | 80 |
| L1 Cache per SM | 64 kB | 128 kB | 128 kB |
| L2 Cache | 4 MB | 5 MB | 48 MB |
| VRAM Bus Width | 256 bits | 320 bits | 192 bits |
| VRAM Amount/Type | 8GB GDDR6 | 10GB GDDR6X | 12GB GDDR6X |
| VRAM Bandwidth (GB/s) | 496 | 760 | 504 |
On paper, the 3080 seems to be the better choice, and not just because it’s cheaper than the 4070 Ti. It has a physically larger chip, in terms of the number of structures — it has the most Graphics and Texture Processing Clusters (GPCs, TPCs) so it can handle more triangles at the same time than the others. It also has the most texture mapping units (TMUs) and render output units (ROPs), the latter being important at high resolutions.
At this point, it’s worth mentioning another criterion for the decision and that’s the resolution of my monitors: 4K. This should make the 4070 Ti a second-place contender to the 3080, but the former has two major positives to it: clock speed and the amount of L2 cache.
With a reference boost clock of 2.61 GHz, it’s almost 50% higher than the other two models, and that more than makes up for the relative lack of components. The peak FP32 throughput, for example, is 40.3 TFLOPS. The 2080 Super gets by with 11.2 and the 3080 is 29.8 — for AI work and offline rendering, this is a big difference.

And there’s the L2 cache. AMD’s RDNA 2 architecture showed just how important the cache system is to gaming, with the L4 Infinity Cache easing the load on the VRAM. Nvidia has always used a simple two-tier cache hierarchy and very large individual tiers can result in increased latencies; the much higher clock speeds, though, would offset this.
Ampere and Ada share very similar Tensor Core structures — it might look like the 2080 Super has the upper hand here, but the newer architectures have cores with double the operations per clock than the old Turing design.
So given what I was going to be using the card for, the choice became simple. Now, the only thing left to do was pick which brand and model of 4070 Ti to go with, but that was easy. I just went with the cheapest one, which turned out to be a Zotac RTX 4070 Ti Trinity OC. Normally I wouldn’t have bothered with any AIB vendor’s overclocked model but this one just so happened to be cheaper than everything else.
Great expectations for the new card?
Of course, I already knew what the 4070 Ti was like compared to the 3080 because Steve had already thoroughly tested it. With a geometric average frame rate 21% higher than the 3080, the new Ada card was underperforming against the paper specifications (the 4070 is 35% higher in all rendering metrics than the Ampere card) but that’s often the case.
The only problem was that the 2080 Super wasn’t included in those tests. However, it was included in Steve’s reviews for the RTX 3070, 3080, and 3090 cards. In the 4K tests, these three graphics cards averaged out, compared to the Turing board, like this:
- RTX 3070 = 20% higher Lows, 19% higher Average
- RTX 3080 = 59% higher Lows, 61% higher Average
- RTX 3090 = 77% higher Lows, 79% higher Average
From the 4070 Ti review, its 4K geomean figures worked out like this:
- RTX 3070 = 57% higher Lows, 61% higher Average
- RTX 3080 = 20% higher Lows, 21% higher Average
- RTX 3090 = 4% higher Lows, 6% higher Average
So combining all of these figures, I estimated that the 4070 Ti could be between 90% and 95% faster than my old 2080 Super. Could being the operative word, though, as different test machines and different benchmarks were all used.
How all of this would fare on my Intel Core i7-9700K, Asus Z390 board, 16GB DDR4-3000 computer was another matter entirely. Such a significant leap in performance may well end up showing clear signs of a benchmark being system limited. It would all come down to the individual tests.
Not that I managed to get very far with those when the new card did arrive. It worked perfectly well for roughly 8 hours before one fan controller and the LED controller decided to pack up the show and head for the beach. The pretty lights I could live without but the dead fan controller handled two out of the three fans, so that was definitely not acceptable. One quick RMA (and by quick, I mean 5 days…) later and we were back in business.
First analysis with micro-benchmarks
The very first set of tests I ran on the new 4070 Ti was a small benchmark suite by someone who just goes by the name Nemez. I came across her work via the team at Chips and Cheese and it’s a Vulkan-based series of tests, designed to produce throughput and latency figures for fundamental GPU operations.
Although I ran through all of the tests offered by the suite, the three that I was most interested in were the fused multiply-add calculations and the bandwidth and latency benchmarks for the cache and memory systems. The first one (usually abbreviated to FMA) is the meat-and-potatoes of most GPU operations; the second test works out how many fast data can be transferred to/from the SM, and the latter is how many nanoseconds of latency is involved in those transfers.
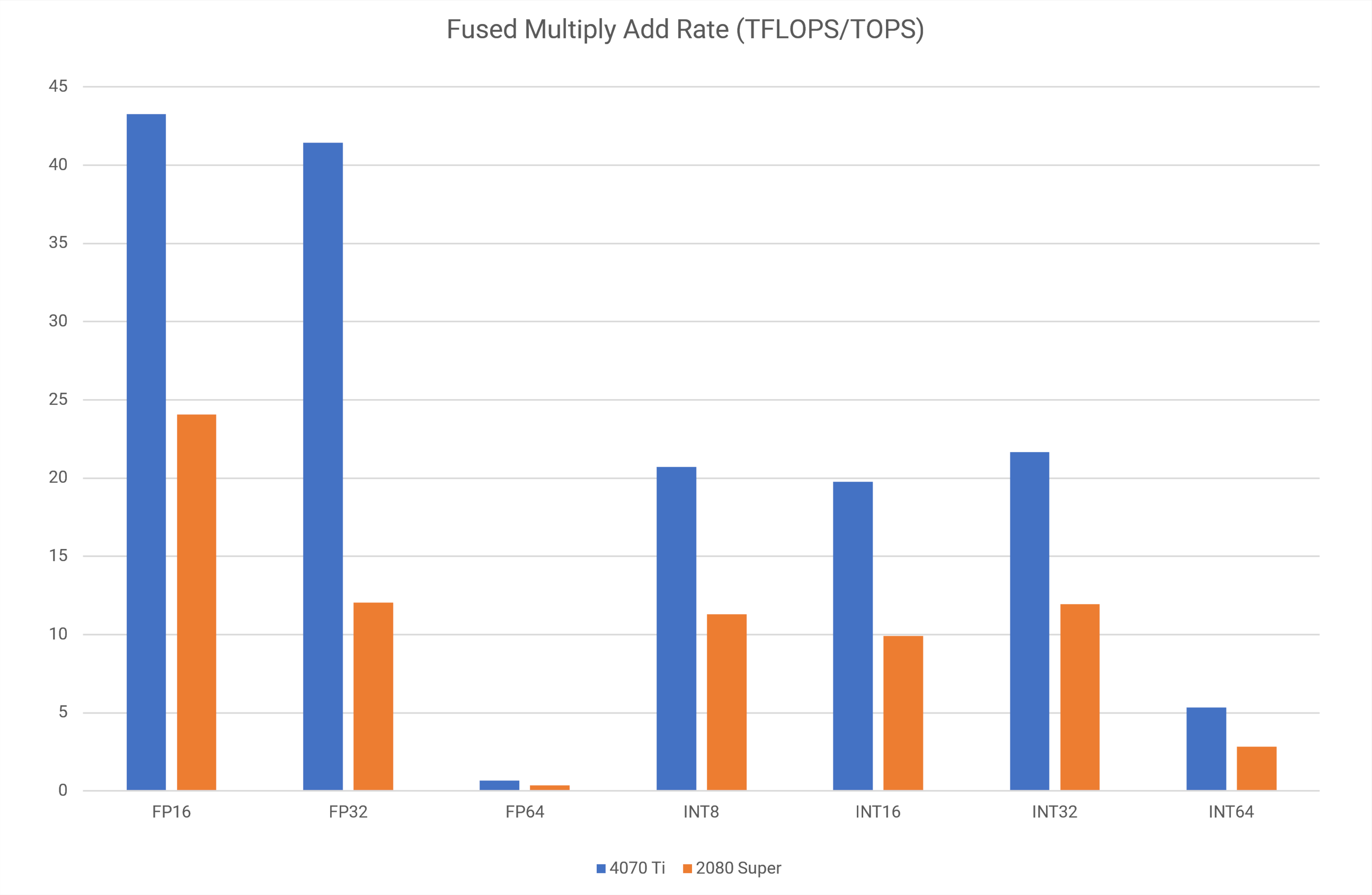
Looking at the FMA results first, remember that the 4070 Ti has a peak FP32 throughput of 40.3 TFLOPS and an INT32 peak of 20.1 TOPS. So why is my card a bit better than this? Yes, it’s a factory overclocked model, but its Boost clock is just 2.625 GHz — a mere 0.6% faster. Here, we’re seeing a peak FP32 rate of 41.4 TFLOPs, an increase of 2.7%.
The simple truth is that Nvidia’s cards will boost beyond their reference clocks, if they’re not hitting the power or thermal limit. During the test, the 4070 Ti was actually running at 2.835 GHz, equating to a theoretical peak FP32 rate of 43.5 TFLOPS. The 2080 Super was doing the same thing, hence why its figures are higher than expected too.
The difference between the new and old graphics cards ranged from 80% (FP16) to 244% (FP32). Although I wasn’t expecting to see the latter figure in games, there were going to be plenty of cases where I would see that level of improvement.
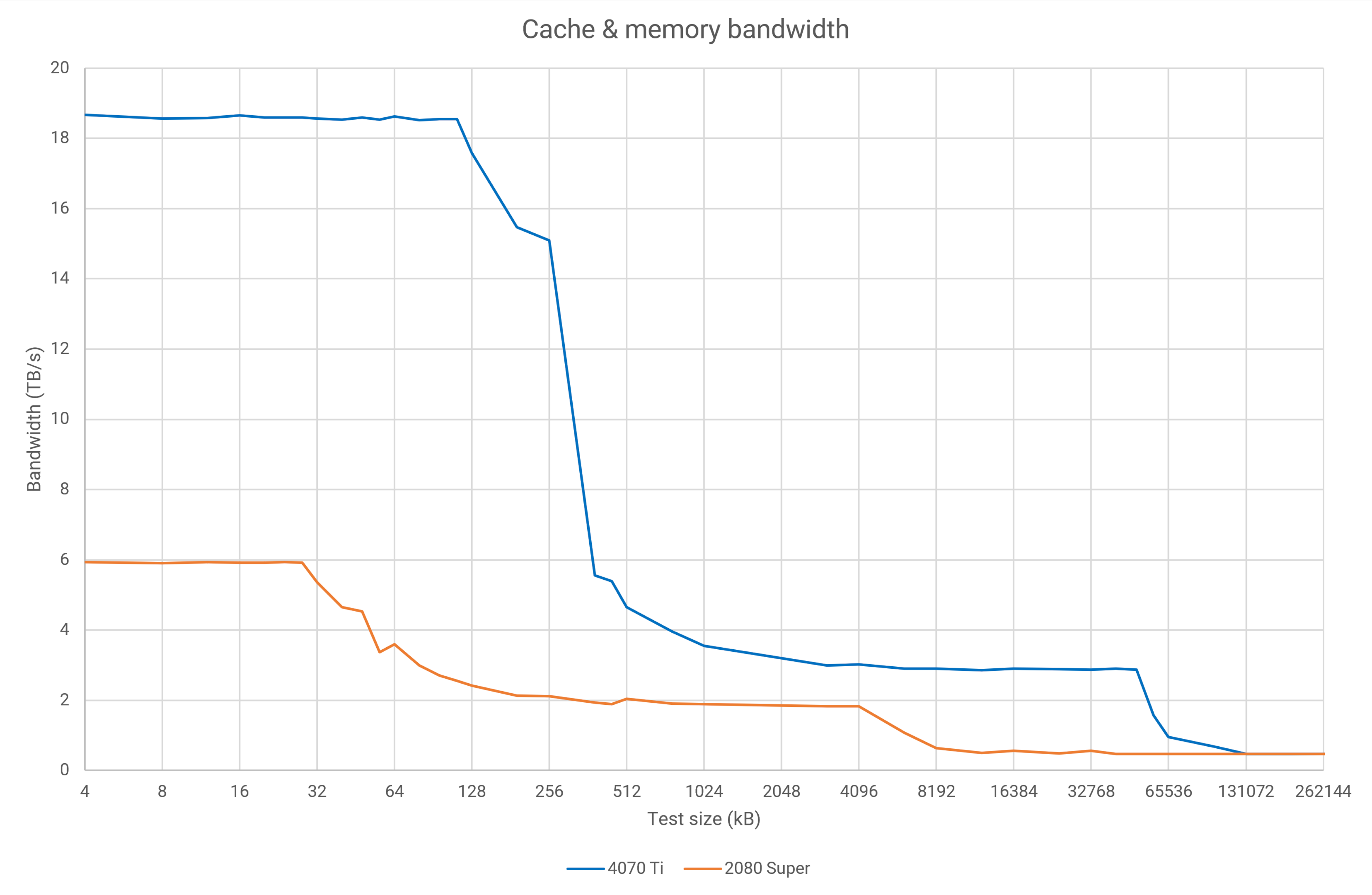
The bandwidth test uses Vulkan compute shaders to calculate the data transfer rate across multiple test sizes, using all of the SMs in the GPU. Turing chips have an L1 cache of 96 kB that is partitioned by the driver. In graphics mode, 64 kB will be set as shared memory for shaders, with the remaining 32 kB as L1 data cache/texture cache/register file overspill.
However, in compute mode, that cache can be set as 32 kB shared/64 kB data or the other way around. With the 2080 Super hitting expected L1 bandwidths, the drop at the 32 kB stage shows that the drivers are interpreting the Vulkan shaders as being ‘graphics’, hence just 32 kB of data cache.

In Ada Lovelace, there is 128 kB of L1 cache in total but the cache partitioning is more complex. The drivers are now judging the test to be in ‘compute mode’ because the bandwidth drops at 112 kB, indicating that 16 kB is being used as shared memory and the rest as data cache.
It does make me wonder how many other applications aren’t being ‘read’ correctly by the drivers. But no matter, as the rest of the test performs exactly as expected — the 4070 Ti’s 48MB of L2 cache, higher clock speeds, and the greater number of SMs are clearly shown. And in both cards, once the test size runs outside of cache limits, the bandwidths are virtually identical, because the data is being pulled from VRAM.
Something was particularly interesting, to me at least, was the difference in measured L1 cache bandwidth compared to the theoretical value. The 2080 Super was almost hitting 100%, whereas the 4070 Ti was around 92%. Perhaps it’s just an oddity of the test itself.
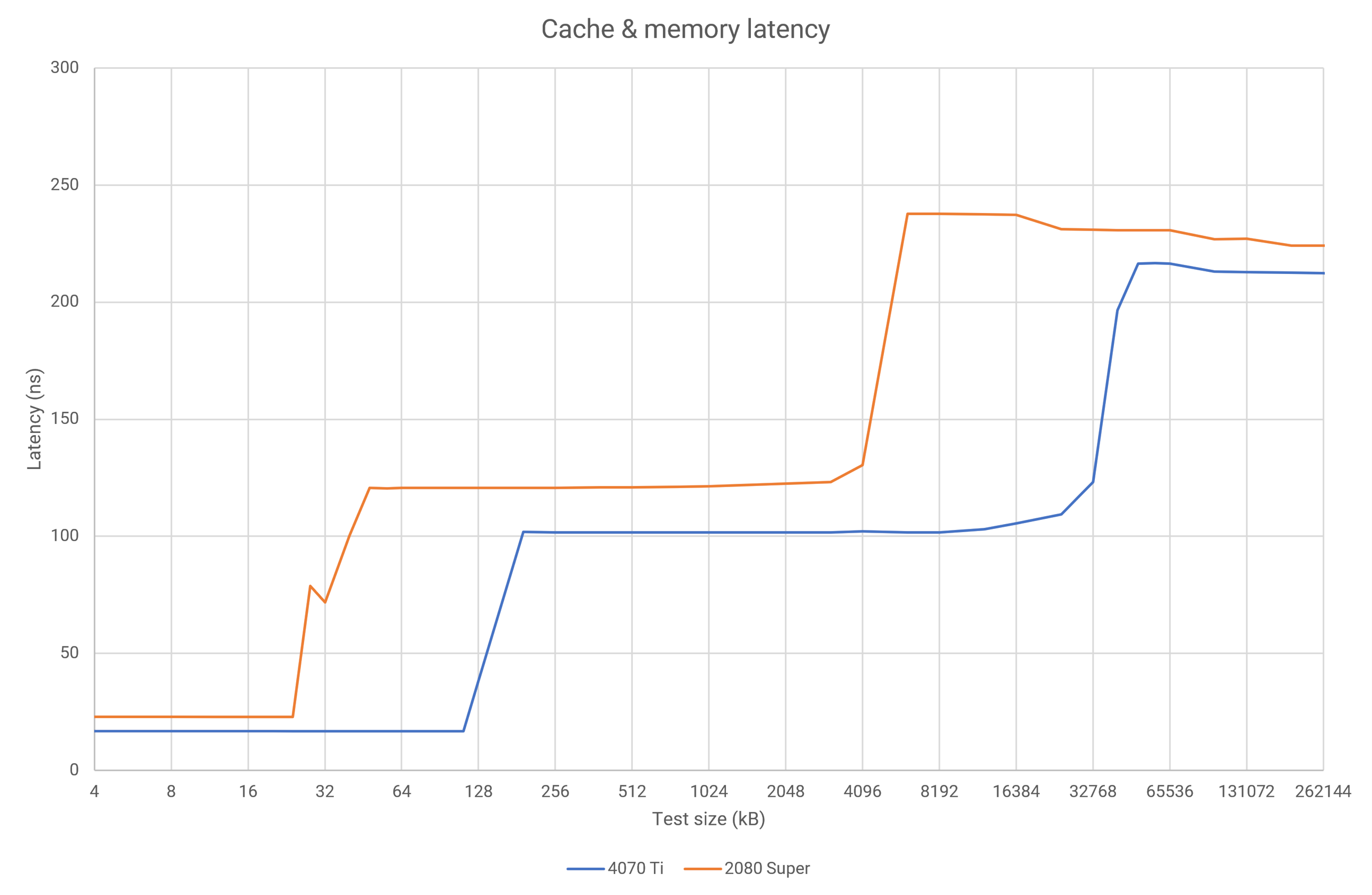
The latency results confirmed what I already had suspected — Nvidia’s done nothing to reduce the number of cycles for L1 cache read/writes in Ada, as the lower latency of the 4070 Ti (24% lower) is purely down to the higher clock speeds (each Ada cycle is 30% quicker than a Turing cycle). However, it is impressive that despite increasing the L2 cache size by a factor of 12, the overall latency is still lower than in Turing.
So compute rates and bandwidth are all way up and overall latencies are better too, which is ideal for the intended use of the new graphics card. No surprise, of course, but good that it’s working out as expected.
Second analysis with synthetic benchmarks
Testing GPUs is tiresome work. Lots of repetitions: configuring benchmarks and games, switching between different hardware and software, multiple runs for reliability, retesting odd-looking results, again and again, and again. Since I didn’t want to spend a huge amount of time on this aspect (i.e. I just wanted to get on and use the thing), I ran a handful of standard benchmarks anyone can try.
To start with, I used the Blender, V-Ray, and 3DMark benchmarks. All nice and simple to use, with no settings to worry about or the like.
| Blender 3.10.0 (Samples per minute) | RTX 2080 Super | RTX 4070 Ti | % Difference |
| Monster scene | 987 | 3566 | +261% |
| Junk Shop scene | 622 | 1602 | +158% |
| Classroom scene | 614 | 1756 | +186% |
Nothing gets rendered onto the screen in these tests, it’s all behind-the-scene calculations, so to speak. But the Monster test clearly shows just how much FP32 performance the 4070 Ti has over the 2080 Super. The other tests are obviously less focused on that aspect of the GPU, but the improvement is still welcome — we do a lot of Blender work in my household, so it was very well received.

| V-Ray 5.0.2 | RTX 2080 Super | RTX 4070 Ti | % Difference |
| GPU CUDA (vpaths) | 672 | 2260 | +236% |
| GPU RTX (vrays) | 851 | 2809 | +230% |
The V-Ray GPU benchmarks are designed to run on Nvidia cards only, as both tests use CUDA. The first test is classic offline rendering, similar to Blender, but the second one accesses the ray tracing cores in the GPU.
It’s a shame that Chaos’ software is so hardware-locked but it’s not a package that I use very often (if at all, these days), as there are renders available that are just as good and completely open source. At least the data provides further confirmation of the compute performance uplift.
So with the increase in raw compute easily demonstrated (I didn’t have time to explore any AI or data analysis packages, unfortunately), it was time to test the ‘graphics’ part of the new graphics card.
| 3DMark (Average fps shown) | RTX 2080 Super | RTX 4070 Ti | % Difference |
| Speed Way | 22 | 54 | +145% |
| Port Royal | 32 | 65 | +104% |
| DXR Feature Test | 22 | 68 | +209% |
| Time Spy Extreme (GT1) | 34 | 69 | +105% |
| Fire Strike Ultra (GT1) | 39 | 77 | +94% |
UL’s 3DMark uses Direct3D to do all of the rendering, but in the case of the first three tests, the DirectX Ray Tracing pipeline (DXR) is also utilized; for the Feature Test, almost all of the graphics are produced this way. The benchmarks are also designed to load up the CPU as little as possible, so the above results represent a best-case scenario for the new graphics card. The biggest surprise was the DXR improvement but only because one has to take Nvidia’s word when it comes to the performance of its ray tracing units.
For the 2080 Super, the ‘RT TFLOPS’ (whatever that’s supposed to be) is a claimed 33.7, whereas it’s 92.7 for the 4070 Ti — an increase of 260%. The 3DMark test doesn’t quite match that figure but it’s enough of an improvement to verify that the increased number of RT units, the higher shader throughput, and the larger and faster L2 cache all go a big way to raising the ray tracing performance.
At the moment, I’m less interested in using it a lot in games (there’s only a handful of titles where it really shines) and more in exploring lighting models in development engines and code snippets. I’m not getting more RT features, of course, just more performance.
One advantage of using 3DMark is being able to loop the benchmarks endlessly, allowing me to use GPU-Z to log the average board power consumption figures during those tests. While there may be some doubt over the precision of the real-time figures, the use of a wall socket power recorder meant that I could confirm the average figures were accurate enough to be used.
| Perf per watt (Average fps per watt used) | RTX 2080 Super | RTX 4070 Ti | % Difference |
| Speed Way | 0.11 | 0.24 | +128% |
| Port Royal | 0.14 | 0.24 | +74% |
| Time Spy Extreme (GT1) | 0.13 | 0.26 | +91% |
| Fire Strike Ultra (GT1) | 0.16 | 0.28 | +74% |
The 4070 Ti, on average, used 11% more power than the 2080 Super in the 3DMark tests (the DXR Feature Test was skipped for this analysis), but the mean performance improvement was 120% — hence the above ‘Perf per watt’ figures.
So, more than happy with the compute and synthetic performance, now it’s time to look at rendering workloads found in games.
Third analysis with gaming benchmarks
For the GPU reviews you read on TechSpot, almost every benchmark result comes from sampling frame rate data during actual gameplay, to provide the most realistic graphics workloads the cards are likely to experience. The downside to using this method is that it’s very time-consuming — you can’t just leave the test to do its thing, while you work on something else. To that end, I took a collection of games that offer built-in benchmark modes, ran those, and used CapFrameX to collect the necessary data (instead of using the game’s reported statistics).

Another aspect to bear in mind with built-in benchmarks is that the graphics load is rarely the same as that experienced during the game. For example, in Assassin’s Creed: Valhalla, the camera swings around a town, showing an epic vista with huge draw distances, but when you actually play the title, the camera is almost always in fixed third person, barely above the ground. So while the rendering isn’t fully representative of the game itself, it is still using the same engine and shader routines.
All tests were run 5 times, with the data then averaged to produce the mean and 1% low frame rates. The benchmarks were done with no upscaling enabled, and then repeated for FSR and/or DLSS set to Balanced. Lastly, where a game supports it, HDR was enabled.
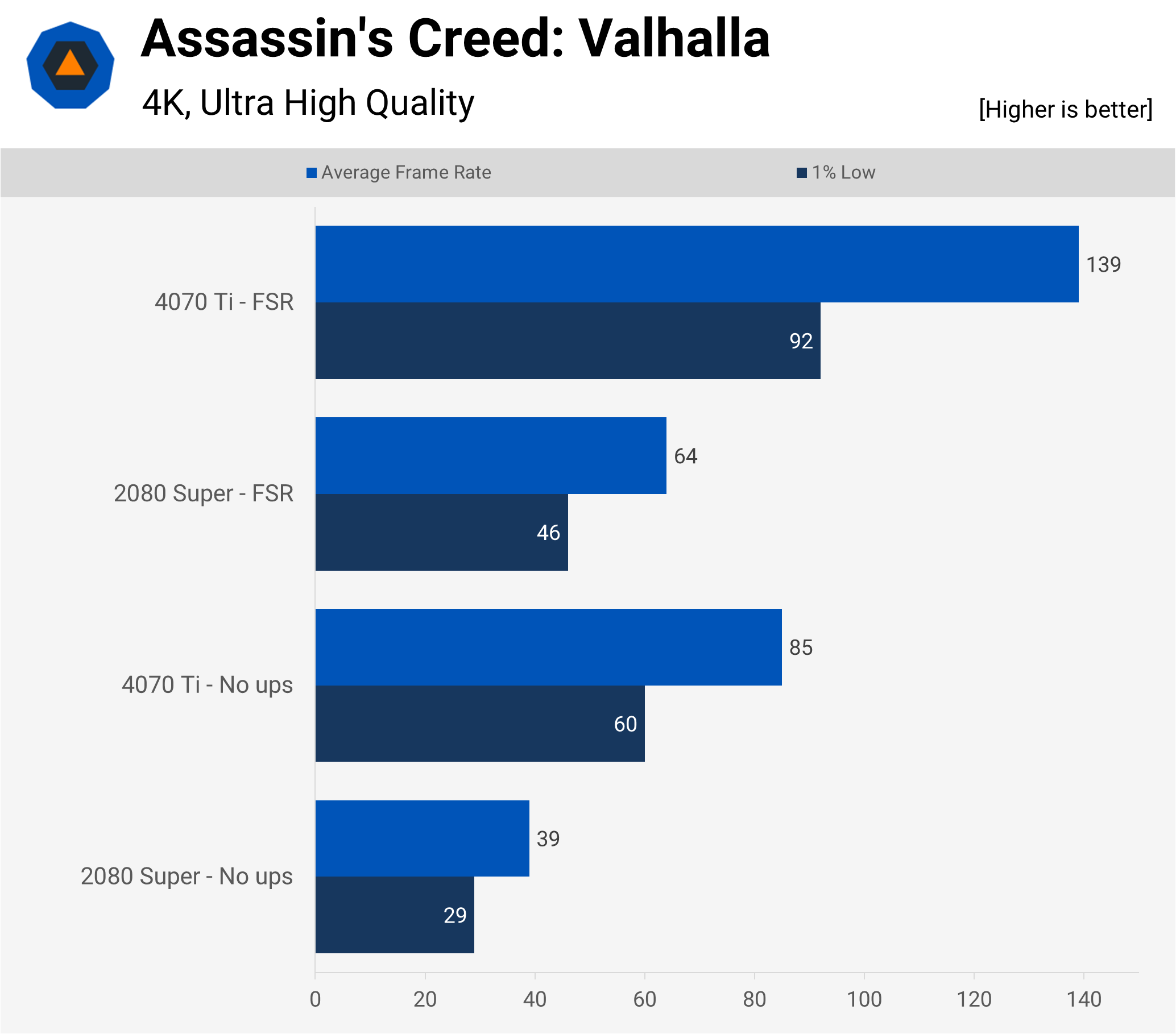
First up is the game I’ve just mentioned, which uses Ubisoft’s Anvil engine for all of the rendering duties. This software package was used for the very first Assassin’s Creed game and over the years it’s been updated to include pretty much every graphics trick in the book (bar ray tracing).
At Ultra High quality settings, the benchmark took its toll on the 2080 Super, but applying FSR 1.0 provides a much-needed boost. The 4070 Ti, on the other hand, copes perfectly well, with an average fps improvement of around 117% (with or without FSR enabled). Visually, it’s better looking with no upscaling involved, although setting it to Quality mode helps a lot.
Valhalla originally launched without any upscaling option, but it was added later in a patch; Ubisoft chose not to update the engine to offer ray-traced shadows or global illumination. A sensible choice really, as it’s not a game that runs very rapidly.
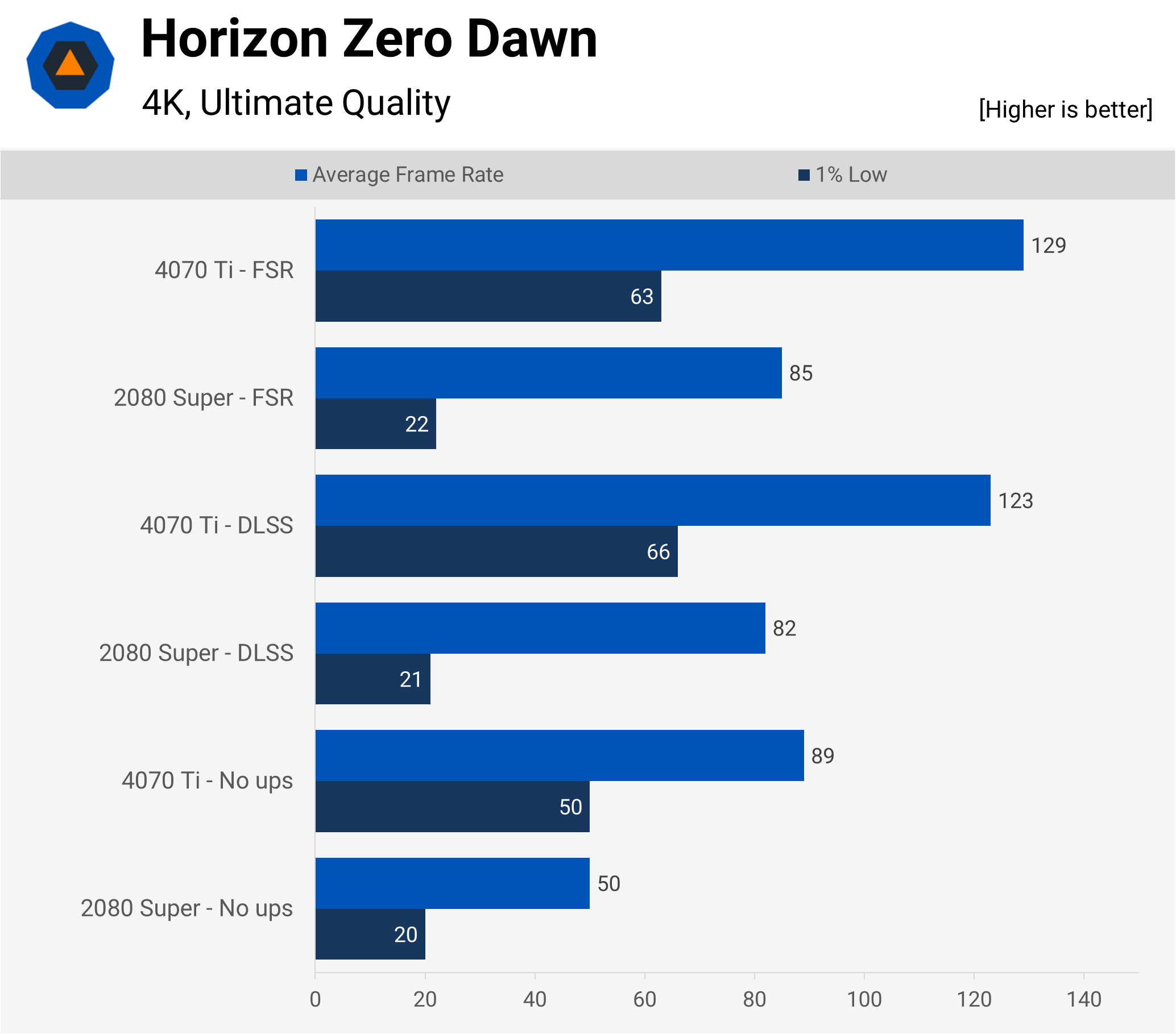
Next up, and from the same year, is Guerrilla Games’ Horizon Zero Dawn, using their own Decima engine. Like Valhalla, there’s no ray tracing, but three upscaling options are provided.
This particular test underwent a lot of additional runs and some resolution scaling checks, as the 1% Low behavior was especially odd with the 2080 Super. Using FSR or DLSS with the 4070 Ti produced no more than 52% improvement in the average frame rate, compared to the Turing card. So what’s going on here?
It turns out that the built-in benchmark in Horizon Zero Dawn is rather CPU/system heavy as evidenced by the fact that at 720 p with upscaling, the 4070 Ti’s 1% low and average frame rates were 70 and 138 respectively — just a fraction lower than at 4K. This is also the case during real-time gameplay, but at no point did the game feel sluggish at 4K with upscaling.
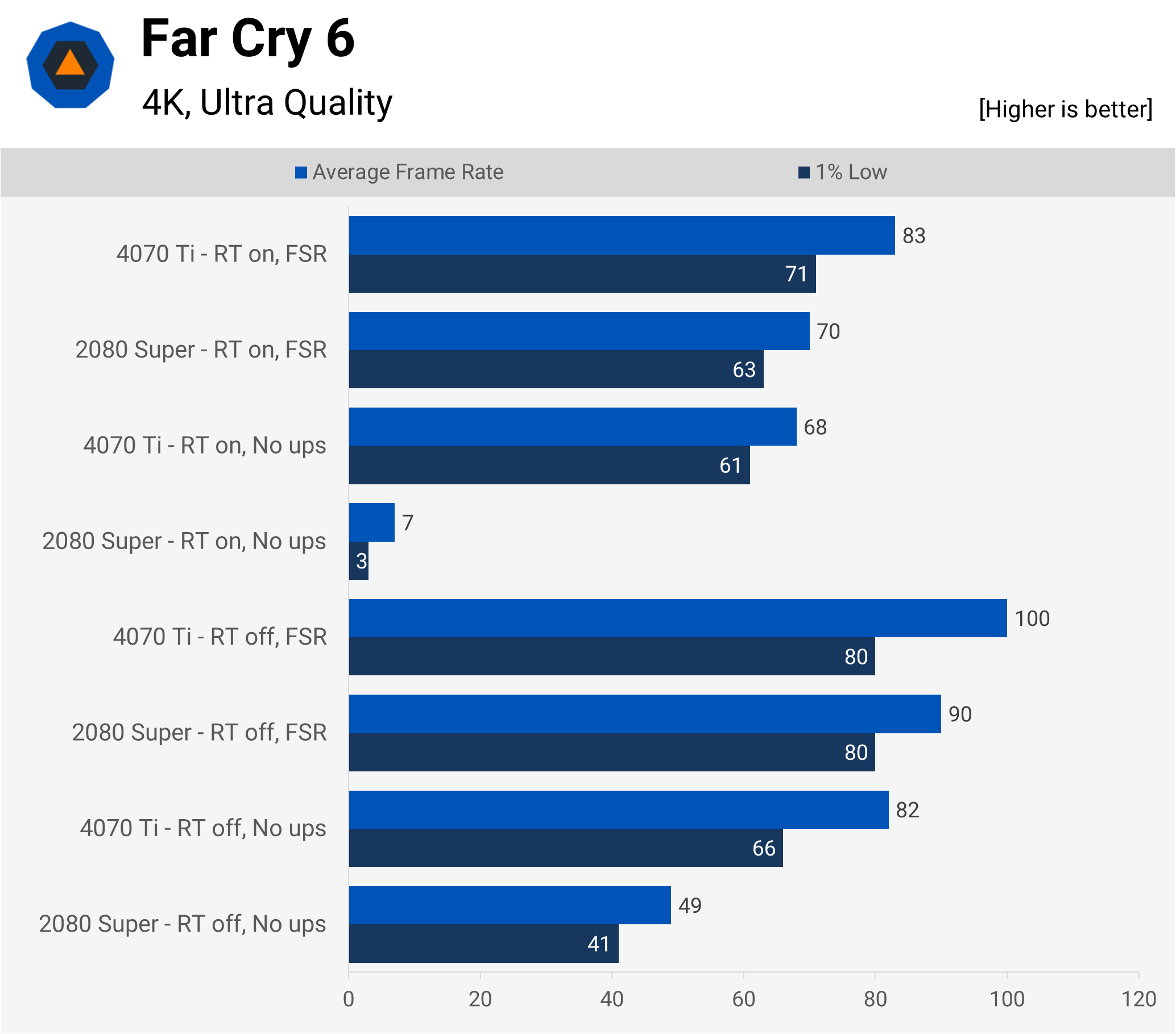
Another Ubisoft title, but this time using their Dunia engine (which began life as an updated CryEngine). Ray tracing and upscaling are both options, although the former is only used for shadows and reflections. It provides a marked improvement to the visuals in some areas but it’s not something that transforms the whole view.
No matter what upscaling is used, the 2080 Super handles 4K quite well, but ray tracing absolutely kills it — this is almost certainly down to the settings pushing the VRAM requirement over the 8GB available on that card and the engine doesn’t manage this issue properly. With 12GB, the 4070 Ti doesn’t suffer from this problem and only takes a 17% drop in the average frame rate with ray tracing enabled (and no upscaling).
However, Far Cry 6 is another benchmark that can be pretty demanding on the CPU/system. Dropping the resolution right down to 720p, and leaving RT and upscaling both on, results in a 1% Low of just 77 fps and an average of 97. Without ray tracing, things fare a little better, but the rest of my PC is somewhat restricting.
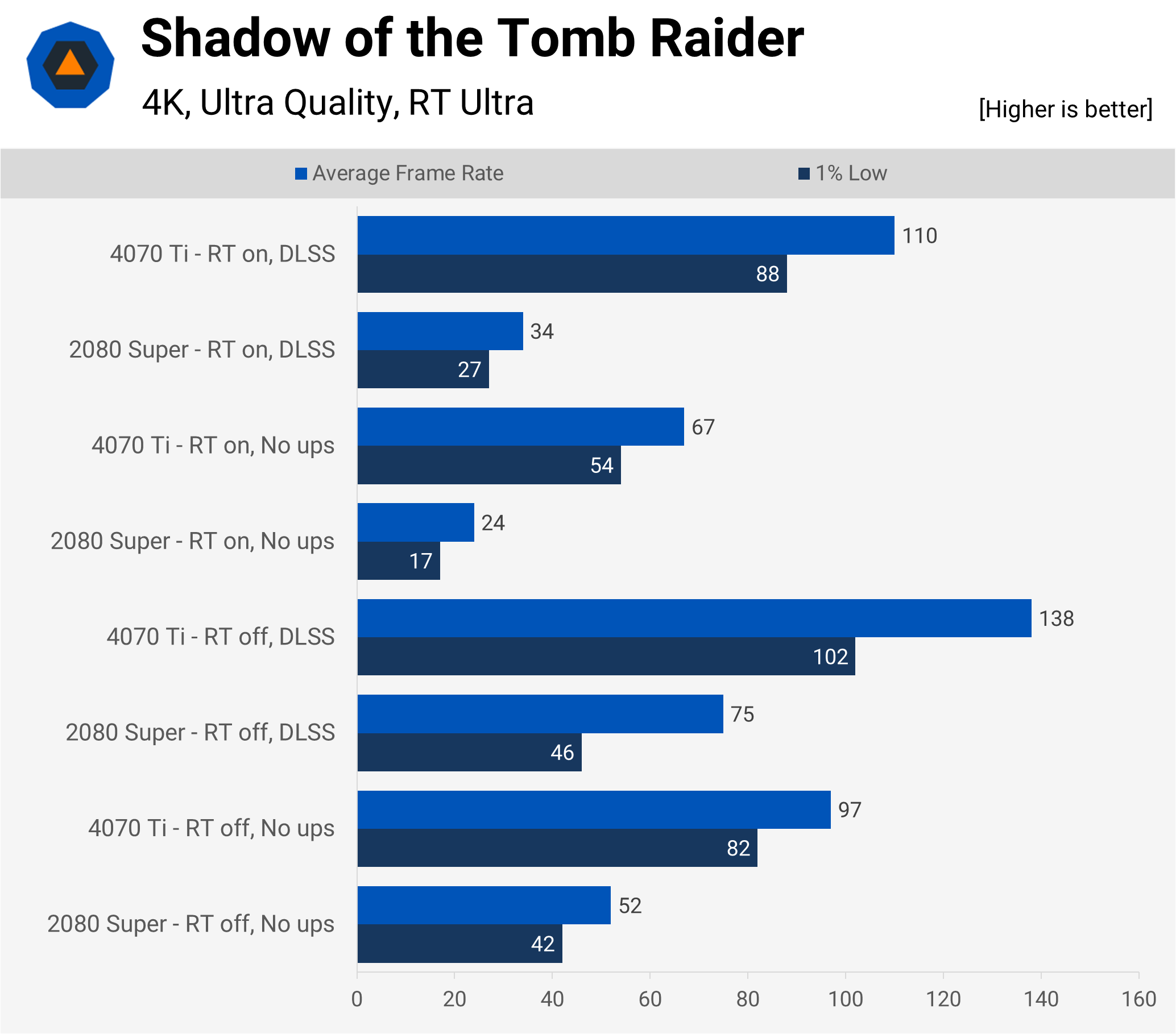
Developed by Eidos-Montréal, using their own in-house engine, Shadow of the Tomb Raider is an example of a game with a very limited implementation of ray tracing — only shadows get done via the DXR pipeline and it’s such a small difference that it’s just not worth enabling it. The RTX 2080 Super certainly struggled with this setting, though, and even the use of DLSS didn’t help all that much.
The new Ada Lovelace GPU also took a sizable hit to its performance, though upscaling pulled it back and when set to Quality mode, the frame rate and visuals were both fine. The game is perfectly fine without having super-sharp shadows all over the place.
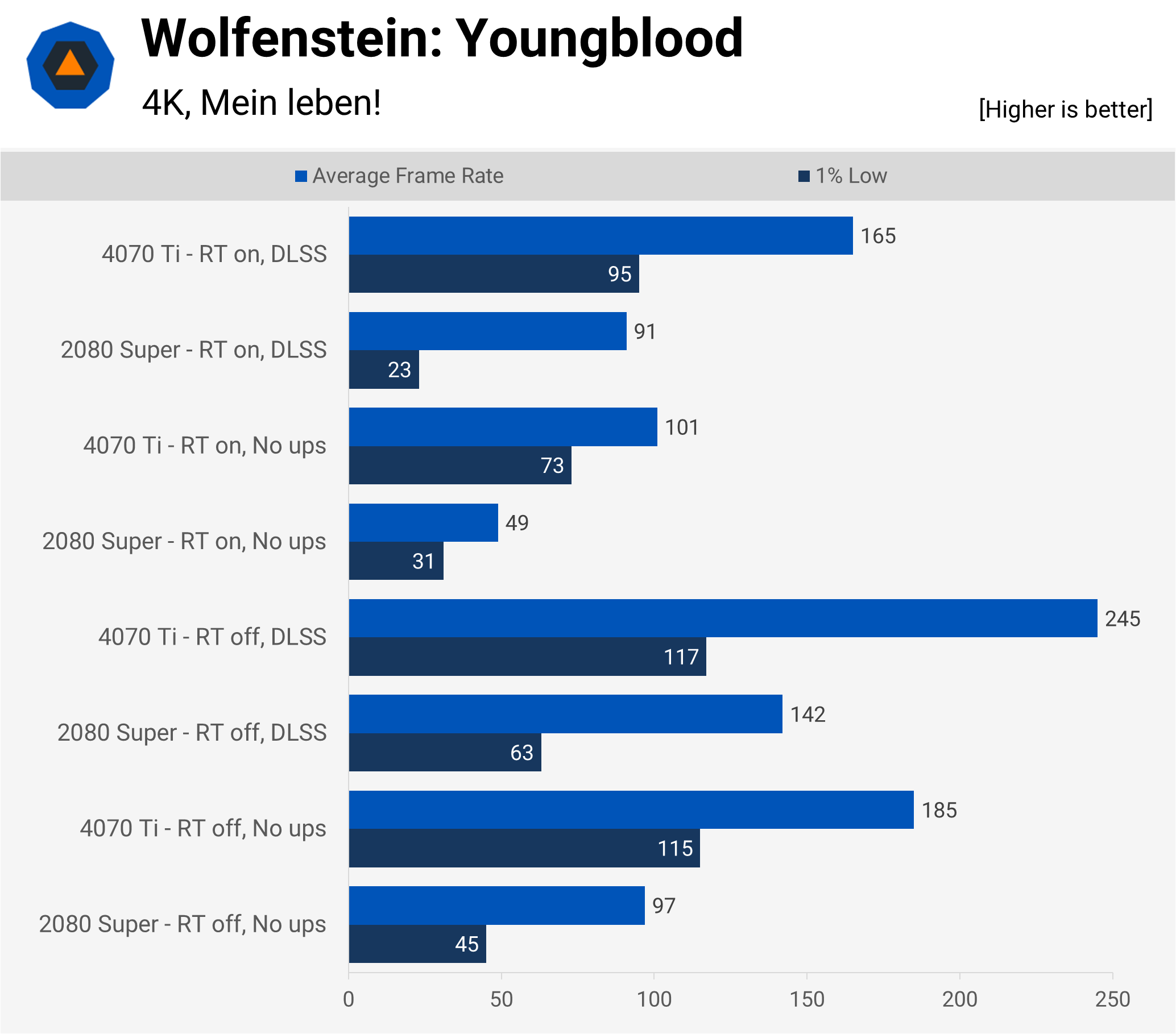
Another early adopter of RT is Wolfenstein: Youngblood, the somewhat mediocre entry in the otherwise excellent series of WWII-meets-the-occult games. Unlike the benchmarks prior to this title, Youngblood uses id Software’s id Tech 6 engine, which runs on Vulkan and OpenGL (the others uses Direct3D). That means ray tracing is accessed via API extensions, which should give better performance, in theory.
Except it doesn’t in this game and just as with Shadow of the Tomb Raider, the visual gains just aren’t worth the drop in frame rate. Or at least that was the case with the 2080 Super; the new card, on the other hand, has enough performance excess to not require upscaling.
The 1% Lows were all over the place in this benchmark, requiring dozens of runs and outlier rejections to get any semblance of a decent statistic. Given that this figure improves substantially, with both cards, when using DLSS, it shows that these variations weren’t a result of a CPU bottleneck — it’s very much a rendering issue.
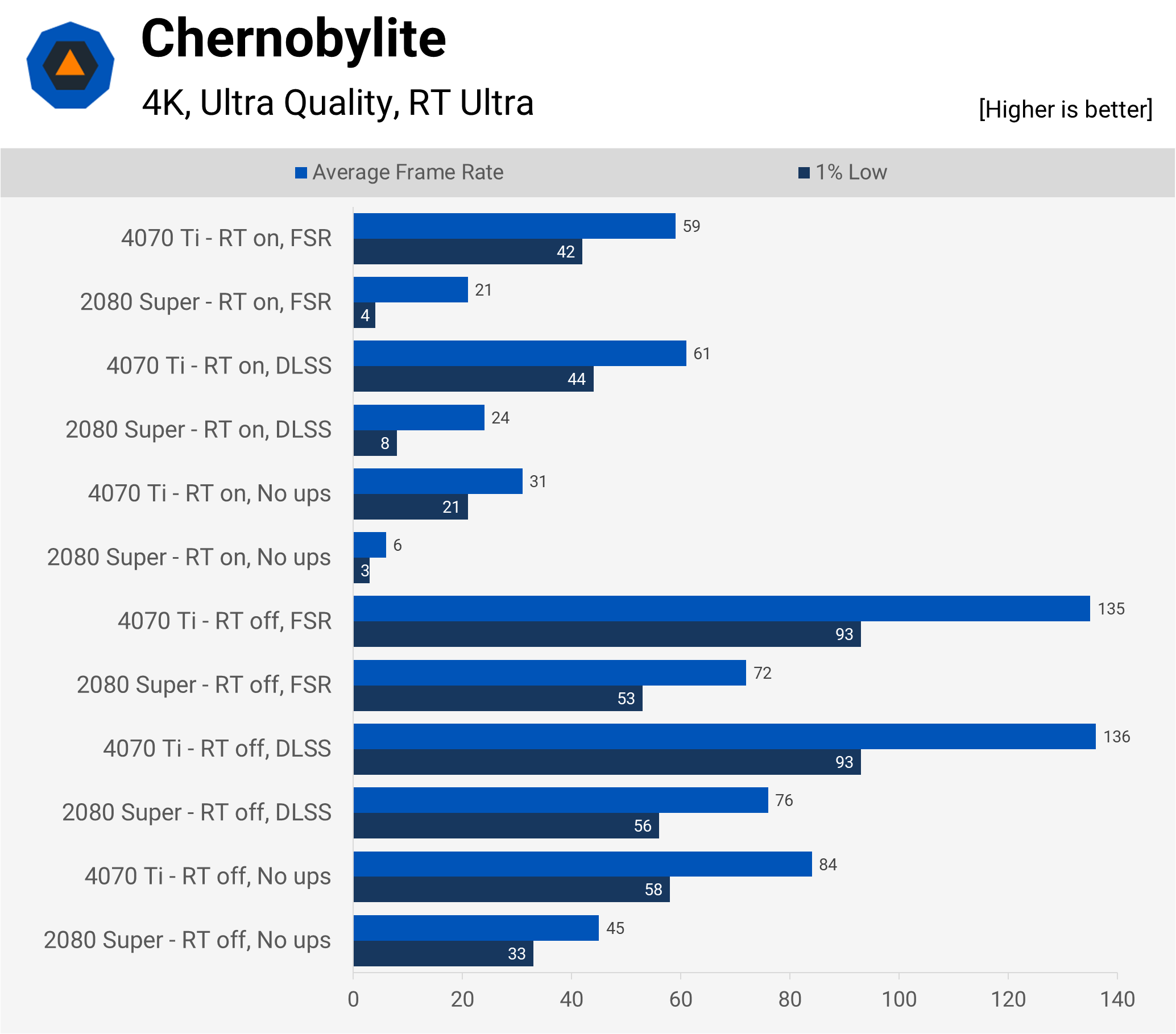
Chernobylite is a recent title, from a small Polish development team, and uses Unreal Engine 4 to produce some truly spectacular scenery, especially with HDR and ray tracing both in use. There is a price to be paid for all the pretty visuals and even accounting for the benchmark’s preference for sweeping camera views, rather than the normal first-person position, the 4070 Ti’s performance isn’t great but not terrible, either.
Not even DLSS in Performance mode helped enough to make it worth using RT — it’s a shame really, because it’s one of the relatively few titles that demonstrate how ray tracing can really lift the quality of global illumination. Ascertaining whether this is down to the limits of the new GPU or the use of UE4 wasn’t worth exploring, as new games with RT using Epic’s engine will be using version 5.
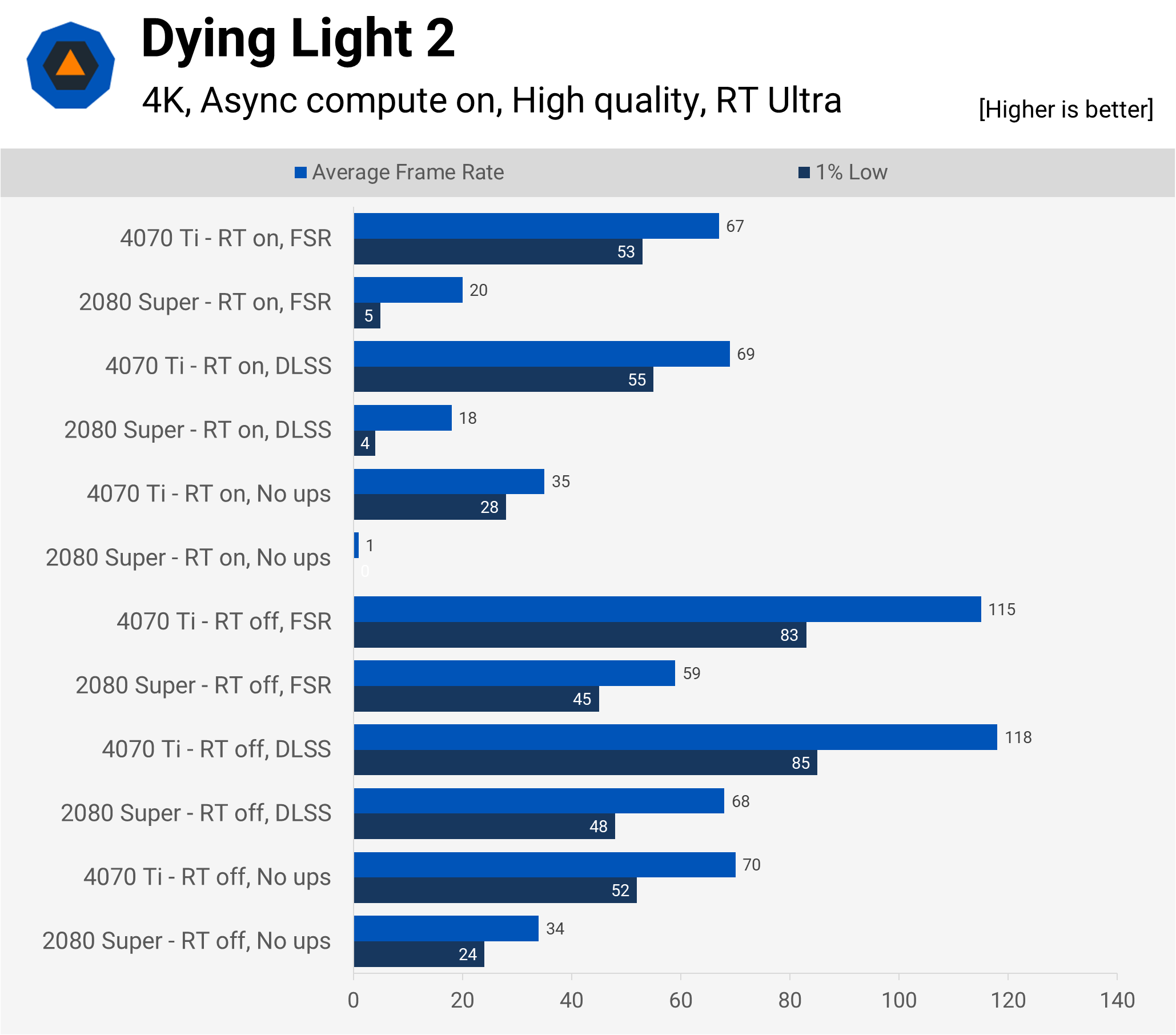
Another engine, another benchmark. This time it’s the clunky sequel to Techland’s Dying Light. The use of ray tracing isn’t quite as effective as it is in Chernobylite, though night time scenery with a flashlight is impressive. The performance? Not so much.
The use of RT, especially if it’s across multiple lighting systems (e.g. reflections, shadows, global illumination) does add quite a bit of extra work for the CPU to crunch through, hence why the use of FSR/DLSS didn’t do much for the 1% low figures.
Dying Light 2 doesn’t really need ultra-high frame rates to be playable though, despite its parkour-n-zombies gameplay. So while the above figures don’t look all that impressive, in-game performance with ray tracing was acceptable with the 4070 Ti. The 2080 Super obviously was just making pretty wallpapers, one every second or so.
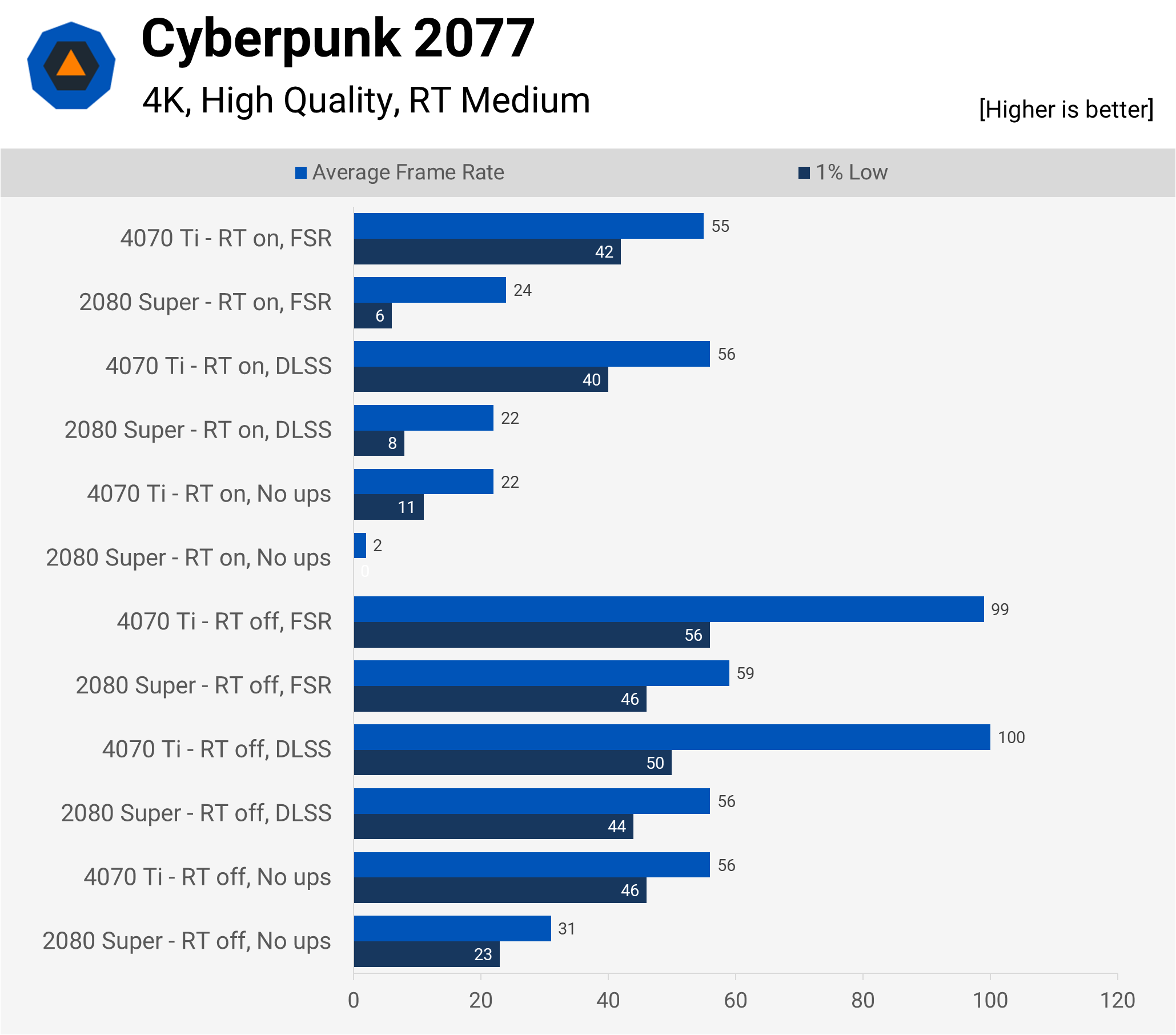
And to finish with, it’s the ray tracing standard that is Cyberpunk 2077. Gaming at 4K with the 4070 Ti was more than achievable, with or without upscaling, but RT was a tad too much for the £800 graphics card.
That’s not entirely fair, as with some tweaking of the settings and the use of FSR/DLSS in Performance mode, both the benchmark and game ran pretty consistently, albeit around the 60 fps mark. For some folks, that’s not good enough, for others and myself, I can cope with that.
The point of all these tests was to: (a) to make sure the replacement card functioned properly, and (b) to see if combining results from different reviews can be used as a reasonably accurate estimator of capability. If you recall earlier in this article, using Steve’s reviews of Ampere cards and the 4070 Ti led me to a figure of +92%. Taking the geometric mean of all the above game benchmarks gives this final assessment.
| Geomean improvement in fps | 1% Low | Avg |
| No RT, no upscaling | +100% | +89% |
| No RT, FSR/DLSS Balanced | +77% | +77% |
| RT on, no upscaling | +1017% | +481% |
| RT on, FSR/DLSS Balanced | +350% | +141% |
A singular experiment like this isn’t quite enough evidence to be fully confident in the estimation but the data does suggest that it’s about right — the reason why the average fps gain isn’t quite so high as expected is down to the CPU limitations in some of the tests.
The RT figures without upscaling should just be ignored, of course, as the RTX 2080 Super generally couldn’t run the majority of those particular benchmarks beyond 1 or 2 fps. But where the use of FSR and DLSS didn’t really help the old Turing card, the new Ada one does especially well. Its geomean 1% low and average frame rates were 55 and 74, respectively, and that’s good enough for me.
So, we’re all done, yes? Time for tea and biscuits? Not just yet.
Final thoughts on the pachyderms in the PC
There are a few things that need addressing before closing this upgrade tale and the first one for me was that damn 12VHPWR connector. Zotac provided a 3-way 8-pin PCIe dongle with the card and it appears well made, suitable in length, etc. However, over the years I’d binned the extra PCIe power cables for my Corsair RM1000 PSU.
The only solution was to get Corsair’s own 2-way PCIe-to-12VHPWR cable for the power supply — it’s more than long enough, uses braided cables, and fits really well but it was an extra £20 that I hadn’t originally expected.

So that £799 MSRP graphics card ended up being £860 in total (840 for the card). I’m not averse to paying a high price for PC components if they fit the role I require them for, but this additional expense could easily have been avoided if Nvidia had just used the standard PCIe power connectors. With a TDP of 285W, two 8-pin sockets would be more than sufficient and the card’s PCB is plenty big enough to house them.
While we’re on the subject of price, the majority view of the 4070 Ti’s sale tag is that it’s way too high for a 70-series model and I wholeheartedly agree with that. It’s at least 33% higher than the 3070 Ti and 60% higher than the 2070 Super. Nvidia originally wanted to fob this off market this GPU as being an 80-class product and on that basis, its MSRP is only 11% more than the 2080 Super’s. But it was supposed to be a ‘bottom end’ 4080, not a new Super.

All that said, I don’t think there’s going to be any paradigm-shifting change in the market prices for GPUs any time soon (if at all) and I don’t really care what it’s called. Nvidia could have named it the RTX Slartibartfast for all I care — it was the feature set and performance uplift that mattered, and both of those were comfortably within the price bracket I was willing to accept. Had the green giant stuck to its original plan and released it as an £899 4080, then it’s possible that I might have gone down a new 3080 route instead.
And if there was better software support for AMD’s graphics cards, I probably would have given the Radeon RX 7900 XT a serious look. While its ray tracing performance isn’t as strong as the 4070 Ti’s, it’s still better than my old 2080 Super, and it has plenty of compute performance and VRAM. The only downside is that the 7900 XT is around £60 to £70 more expensive than the Nvidia card, though I wouldn’t have needed the 12VHPWR cable.

One feature that I’ve not mentioned so far is DLSS Frame Generation (a.k.a. DLSS 3). That’s because I’ve only tried it in one title (Spider-Man: Miles Morales) and even then, it was a very subjective analysis — essentially, I just enabled it and let the household’s Spidey expert cast her opinion on how it feels/looks. I won’t repeat the exact phrases uttered during the experiment but I can paraphrase them in one word: lag.
The game is best played using a controller and after trying it myself and then again using a keyboard and mouse, I can concur that there’s a discernible sluggishness. It’s not quite an actual delay in moving the joysticks about and getting an onscreen reaction; it’s more of a feeling than anything else. Switching to the mouse and keyboard makes it far less noticeable, though. When I have time, I’ll test it out in some other titles, but there’s not a vast array of titles supporting it at the moment.
And with that, it’s time to end this upgrade tale. The new card does perform as expected (mostly so, at least) and it’s a marked improvement over the 2080 Super — not just in performance, but also in efficiency and noise. Time to put it to work!
Shopping shortcuts
- Nvidia GeForce RTX 4070 Ti on Amazon
- Nvidia GeForce RTX 4080 on Amazon
- Nvidia GeForce RTX 3080 on Amazon
- AMD Radeon RX 7900 XTX on Amazon
- AMD Radeon RX 7900 XT on Amazon