

{kind=link}
Enlarge / In this still captured from a video provided by Nvidia, a simulated robot hand learns pen tricks, trained by Eureka, using simultaneous trials.
On Friday, researchers from Nvidia, UPenn, Caltech, and the University of Texas at Austin announced Eureka, an algorithm that uses OpenAI’s GPT-4 language model for designing training goals (called “reward functions”) to enhance robot dexterity. The work aims to bridge the gap between high-level reasoning and low-level motor control, allowing robots to learn complex tasks rapidly using massively parallel simulations that run through trials simultaneously. According to the team, Eureka outperforms human-written reward functions by a substantial margin.
Before robots can interact with the real world successfully, they need to learn how to move their robot bodies to achieve goals—like picking up objects or moving. Instead of making a physical robot try and fail one task at a time to learn in a lab, researchers at Nvidia have been experimenting with using video game-like computer worlds (thanks to platforms called Isaac Sim and Isaac Gym) that simulate three-dimensional physics. These allow for massively parallel training sessions to take place in many virtual worlds at once, dramatically speeding up training time.
“Leveraging state-of-the-art GPU-accelerated simulation in Nvidia Isaac Gym,” writes Nvidia on its demonstration page, “Eureka is able to quickly evaluate the quality of a large batch of reward candidates, enabling scalable search in the reward function space.” They call it “rapid reward evaluation via massively parallel reinforcement learning.”
The researchers describe Eureka as a “hybrid-gradient architecture,” which essentially means that it is a blend of two different learning models. A low-level neural network dedicated to robot motor control takes instructions from a high-level, inference-only large language model (LLM) like GPT-4. The architecture employs two loops: an outer loop using GPT-4 for refining the reward function, and an inner loop for reinforcement learning to train the robot’s control system.
Advertisement
The research is detailed in a new preprint research paper titled, “Eureka: Human-Level Reward Design via Coding Large Language Models.” Authors Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi “Jim” Fan, and Anima Anandkumar used the aforementioned Isaac Gym, a GPU-accelerated physics simulator, to reportedly speed up the physical training process by a factor of 1,000. In the paper’s abstract, the authors claim that Eureka outperformed expert human-engineered rewards in 83 percent of a benchmark suite of 29 tasks across 10 different robots, improving performance by an average of 52 percent.
Additionally, Eureka introduces a novel form of reinforcement learning from human feedback (RLHF), allowing a human operator’s natural language feedback to influence the reward function. This could serve as a “powerful co-pilot” for engineers designing sophisticated motor behaviors for robots, according to an X post by Nvidia AI researcher Fan, who is a listed author on the Eureka research paper. One surprising achievement, Fan says, is that Eureka enabled robots to perform pen-spinning tricks, a skill that is difficult even for CGI artists to animate.
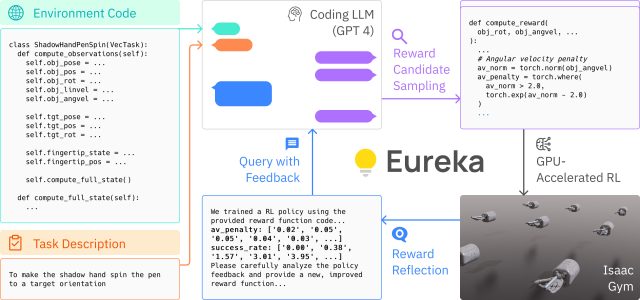 Enlarge / A diagram from the Eureka research team.
Enlarge / A diagram from the Eureka research team.
So what does it all mean? In the future, teaching robots new tricks will likely come at accelerated speed thanks to massively parallel simulations, with a little help from AI models that can oversee the training process. The latest work is adjacent to previous experiments using language models to control robots from Microsoft and Google.
On X, Shital Shah, a principal research engineer at Microsoft Research, wrote that the Eureka approach appears to be a key step toward realizing the full potential of reinforcement learning: “The proverbial positive feedback loop of self-improvement might be just around the corner that allows us to go beyond human training data and capabilities.”
The Eureka team has made its research and code base publicly available for further experimentation and for future researchers to build off of. The paper can be accessed on arXiv, and the code is available on GitHub.