

{kind=link}
Agrandir / Une image générée par l’IA d’un cerveau électronique avec un globe oculaire.
Ars Technica
Lundi, des chercheurs de Microsoft ont présenté Kosmos-1, un modèle multimodal capable d’analyser des images pour le contenu, de résoudre des énigmes visuelles, d’effectuer une reconnaissance visuelle de texte, de passer des tests de QI visuel et de comprendre des instructions en langage naturel. Les chercheurs pensent que l’IA multimodale – qui intègre différents modes d’entrée tels que le texte, l’audio, les images et la vidéo – est une étape clé pour construire une intelligence générale artificielle (AGI) capable d’effectuer des tâches générales au niveau d’un humain.
“Élément fondamental de l’intelligence, le multimodal la perception est une nécessité pour atteindre l’artificiel intelligence généraleen termes d’acquisition de connaissances et l’ancrage dans le monde réel », écrivent les chercheurs dans leur article universitaire, « La langue n’est pas tout ce dont vous avez besoin : aligner la perception sur les modèles linguistiques ».
Des exemples visuels de l’article Kosmos-1 montrent le modèle analysant des images et répondant à des questions à leur sujet, lisant le texte d’une image, écrivant des légendes pour les images et passant un test de QI visuel avec une précision de 22 à 26 % (plus de détails ci-dessous).
-
Un exemple fourni par Microsoft de Kosmos-1 répondant à des questions sur les images et les sites Web.
Microsoft
-
Un exemple fourni par Microsoft d'”incitation à la chaîne de pensée multimodale” pour Kosmos-1.
Microsoft
-
Un exemple de Kosmos-1 faisant une réponse visuelle aux questions, fourni par Microsoft.
Microsoft
Alors que les médias bourdonnent d’actualités sur les grands modèles de langage (LLM), certains experts en IA désignent l’IA multimodale comme une voie potentielle vers l’intelligence artificielle générale, une technologie hypothétique qui sera apparemment capable de remplacer les humains dans n’importe quelle tâche intellectuelle (et n’importe quel travail intellectuel) . AGI est l’objectif déclaré d’OpenAI, un partenaire commercial clé de Microsoft dans le domaine de l’IA.
Dans ce cas, Kosmos-1 semble être un pur projet Microsoft sans l’implication d’OpenAI. Les chercheurs appellent leur création un “modèle de grand langage multimodal” (MLLM) car ses racines résident dans le traitement du langage naturel comme un LLM textuel, tel que ChatGPT. Et cela montre: Pour que Kosmos-1 accepte l’entrée d’image, les chercheurs doivent d’abord traduire l’image en une série spéciale de jetons (essentiellement du texte) que le LLM peut comprendre. L’article Kosmos-1 décrit cela plus en détail :
Publicité
Pour le format d’entrée, nous aplatissons l’entrée sous la forme d’une séquence décorée de jetons spéciaux. Plus précisément, nous utilisons paragraphe ” est une entrée image-texte entrelacée.
… Un module d’intégration est utilisé pour coder à la fois les jetons de texte et d’autres modalités d’entrée dans des vecteurs. Ensuite, les plongements sont introduits dans le décodeur. Pour les jetons d’entrée, nous utilisons une table de recherche pour les mapper dans les incorporations. Pour les modalités des signaux continus (par exemple, image et audio), il est également possible de représenter les entrées sous forme de code discret et de les considérer ensuite comme des “langues étrangères”.
Microsoft a formé Kosmos-1 à l’aide de données provenant du Web, y compris des extraits de The Pile (une ressource de texte en anglais de 800 Go) et de Common Crawl. Après la formation, ils ont évalué les capacités de Kosmos-1 sur plusieurs tests, y compris la compréhension du langage, la génération de langage, la classification de texte sans reconnaissance optique de caractères, le sous-titrage d’images, la réponse visuelle aux questions, la réponse aux questions sur les pages Web et la classification d’images sans prise de vue. Dans bon nombre de ces tests, Kosmos-1 a surpassé les modèles de pointe actuels, selon Microsoft.
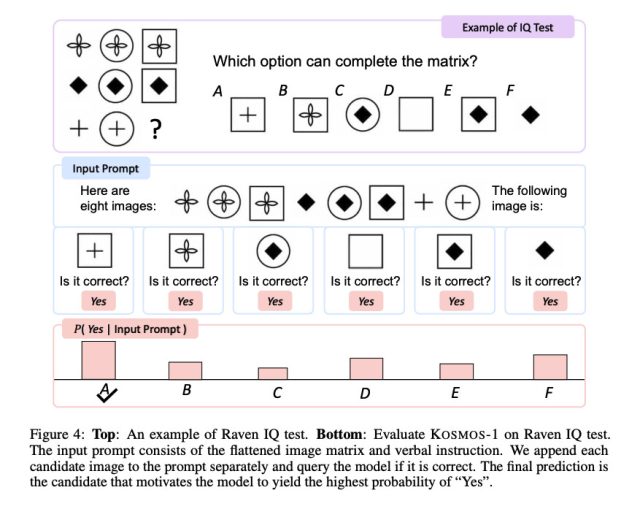 Agrandir / Un exemple du test Raven IQ que Kosmos-1 a été chargé de résoudre.
Agrandir / Un exemple du test Raven IQ que Kosmos-1 a été chargé de résoudre.
Microsoft
La performance de Kosmos-1 sur le raisonnement progressif de Raven, qui mesure le QI visuel en présentant une séquence de formes et en demandant au candidat de compléter la séquence, est particulièrement intéressante. Pour tester Kosmos-1, les chercheurs ont alimenté un test rempli, un à la fois, avec chaque option complétée et ont demandé si la réponse était correcte. Kosmos-1 n’a pu répondre correctement à une question du test Raven que 22% du temps (26% avec un réglage fin). Ce n’est en aucun cas un slam dunk, et des erreurs dans la méthodologie auraient pu affecter les résultats, mais Kosmos-1 a battu le hasard (17%) au test Raven IQ.
Pourtant, alors que Kosmos-1 représente les premières étapes dans le domaine multimodal (une approche également suivie par d’autres), il est facile d’imaginer que de futures optimisations pourraient apporter des résultats encore plus significatifs, permettant aux modèles d’IA de percevoir n’importe quelle forme de média et d’agir en conséquence. , ce qui améliorera considérablement les capacités des assistants artificiels. À l’avenir, les chercheurs disent qu’ils aimeraient augmenter la taille du modèle Kosmos-1 et intégrer également la capacité vocale.
Microsoft indique qu’il prévoit de mettre Kosmos-1 à la disposition des développeurs, bien que la page GitHub citée par l’article ne contienne aucun code évident spécifique à Kosmos lors de la publication de cette histoire.