

{kind=link}
Mercredi, Google a présenté PaLM 2, une famille de modèles de langage fondamentaux comparables au GPT-4 d’OpenAI. Lors de son événement Google I/O à Mountain View, en Californie, Google a révélé qu’il utilisait déjà PaLM 2 pour alimenter 25 produits, y compris son assistant d’IA conversationnel Bard.
En tant que famille de grands modèles de langage (LLM), PaLM 2 a été formé sur un énorme volume de données et effectue la prédiction du mot suivant, qui produit le texte le plus probable après une saisie rapide par des humains. PaLM signifie “Pathways Language Model” et “Pathways” est une technique d’apprentissage automatique créée par Google. PaLM 2 fait suite au PaLM original, annoncé par Google en avril 2022.
Selon Google, PaLM 2 prend en charge plus de 100 langues et peut effectuer un “raisonnement”, une génération de code et une traduction multilingue. Lors de son discours d’ouverture Google I/O 2023, le PDG de Google, Sundar Pichai, a déclaré que PaLM 2 est disponible en quatre tailles : Gecko, Otter, Bison, Unicorn. Gecko est le plus petit et peut fonctionner sur un appareil mobile. Outre Bard, PaLM 2 est à l’origine des fonctionnalités d’IA dans Docs, Sheets et Slides.
 Agrandir / Un exemple fourni par Google du “raisonnement” PaLM 2.
Agrandir / Un exemple fourni par Google du “raisonnement” PaLM 2.
Tout cela est très bien, mais comment PaLM 2 se compare-t-il à GPT-4 ? Dans le rapport technique de PaLM 2, PaLM 2 semble battre GPT-4 dans certaines tâches mathématiques, de traduction et de raisonnement. Mais la réalité pourrait ne pas correspondre aux références de Google. Dans une évaluation superficielle de la version PaLM 2 de Bard par Ethan Mollick, un professeur de Wharton qui écrit souvent sur l’IA, Mollick constate que les performances de PaLM 2 semblent pires que GPT-4 et Bing sur divers tests de langage informels, qu’il a détaillés dans un Twitter fil de discussion.
Jusqu’à récemment, la famille de modèles de langage PaLM était un produit interne de Google Research sans exposition aux consommateurs, mais Google a commencé à offrir un accès limité à l’API en mars. Pourtant, le premier PaLM se distinguait par sa taille massive : 540 milliards de paramètres. Les paramètres sont des variables numériques qui servent de “connaissance” apprise du modèle, lui permettant de faire des prédictions et de générer du texte en fonction de l’entrée qu’il reçoit.
Publicité
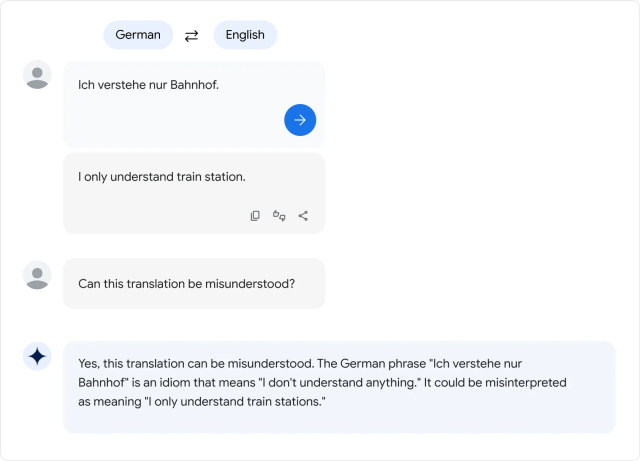 Agrandir / Un exemple fourni par Google de langues de traduction PaLM 2.
Agrandir / Un exemple fourni par Google de langues de traduction PaLM 2.
Plus de paramètres signifie à peu près plus de complexité, mais il n’y a aucune garantie qu’ils soient utilisés efficacement. En comparaison, le GPT-3 d’OpenAI (à partir de 2020) compte 175 milliards de paramètres. OpenAI n’a jamais divulgué le nombre de paramètres dans GPT-4.
Cela nous amène donc à la grande question : à quel point PaLM 2 est-il “grand” en termes de nombre de paramètres ? Google ne le dit pas, ce qui a frustré certains experts de l’industrie qui se battent souvent pour plus de transparence dans ce qui fait fonctionner les modèles d’IA.
Ce n’est pas la seule propriété de PaLM 2 sur laquelle Google a été silencieux. La société affirme que PaLM 2 a été formé sur “un ensemble diversifié de sources : documents Web, livres, code, mathématiques et données conversationnelles”, mais n’entre pas dans les détails sur ce que sont exactement ces données.
Comme avec d’autres grands ensembles de données de modèles linguistiques, l’ensemble de données PaLM 2 comprend probablement une grande variété de matériel protégé par le droit d’auteur utilisé sans autorisation et du matériel potentiellement dangereux extrait d’Internet. Les données de formation influencent de manière décisive la sortie de tout modèle d’IA, c’est pourquoi certains experts ont préconisé l’utilisation d’ensembles de données ouvertes qui peuvent offrir des opportunités de reproductibilité scientifique et d’examen éthique.
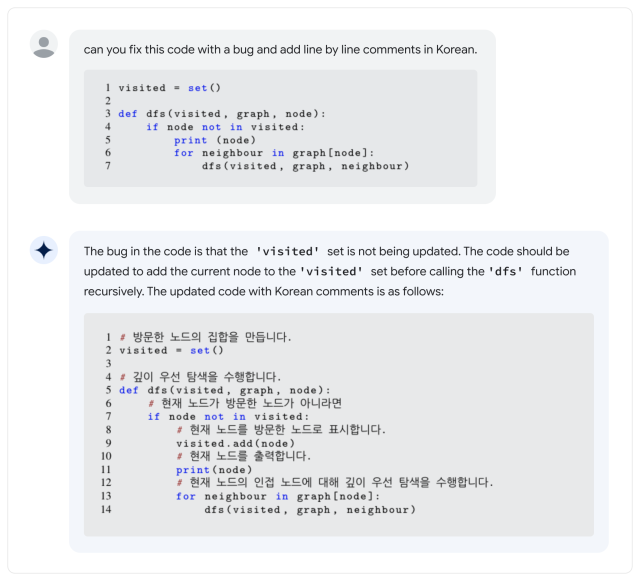 Agrandir / Un exemple fourni par Google de code de programme d’écriture PaLM 2.
Agrandir / Un exemple fourni par Google de code de programme d’écriture PaLM 2.
“Maintenant que les LLM sont des produits (et pas seulement de la recherche), nous sommes à un tournant : les entreprises à but lucratif deviendront de moins en moins transparentes *spécifiquement* sur les composants les plus importants”, a tweeté Jesse Dodge, chercheur au Institut Allen d’IA. “Ce n’est que si la communauté open source peut s’organiser ensemble que nous pourrons suivre le rythme !”
Jusqu’à présent, la critique de cacher sa sauce secrète n’a pas empêché Google de poursuivre un large déploiement de modèles d’IA, malgré une tendance dans tous les LLM à simplement inventer des choses à partir de rien. Au cours de Google I/O, les représentants de l’entreprise ont fait la démonstration des fonctionnalités d’IA dans bon nombre de ses principaux produits, ce qui signifie qu’une large partie du public pourrait bientôt se battre contre les confabulations d’IA.
Et en ce qui concerne les LLM, PaLM 2 est loin d’être la fin de l’histoire : dans le discours d’ouverture des I/O, Pichai a mentionné qu’un nouveau modèle d’IA multimodal appelé “Gemini” était actuellement en formation. Alors que la course à la domination de l’IA se poursuit, les utilisateurs de Google aux États-Unis et dans 180 autres pays (à l’exclusion curieusement du Canada et de l’Europe continentale) peuvent essayer PaLM 2 eux-mêmes dans le cadre de Google Bard, l’assistant expérimental d’IA.