

{kind=link}
Agrandir / Une représentation illustrée de données dans une onde audio.
Méta IA
La semaine dernière, Meta a annoncé une méthode de compression audio alimentée par l’IA appelée “EnCodec” qui pourrait compresser l’audio 10 fois plus petit que le format MP3 à 64kbps sans perte de qualité. Meta indique que cette technique pourrait considérablement améliorer la qualité sonore de la parole sur les connexions à faible bande passante, telles que les appels téléphoniques dans les zones où le service est inégal. La technique fonctionne aussi pour la musique.
Meta a lancé la technologie le 25 octobre dans un article intitulé “High Fidelity Neural Audio Compression”, rédigé par les chercheurs de Meta AI Alexandre Défossez, Jade Copet, Gabriel Synnaeve et Yossi Adi. Meta a également résumé les recherches sur son blog consacré à EnCodec.
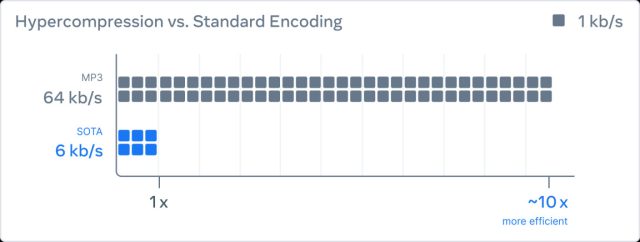 Agrandir / Meta affirme que son nouvel encodeur/décodeur audio peut compresser l’audio 10 fois plus petit que le MP3.
Agrandir / Meta affirme que son nouvel encodeur/décodeur audio peut compresser l’audio 10 fois plus petit que le MP3.
Méta IA
Meta décrit sa méthode comme un système en trois parties formé pour compresser l’audio à une taille cible souhaitée. Tout d’abord, le codeur transforme les données non compressées en une représentation “d’espace latent” à fréquence d’image inférieure. Le “quantificateur” comprime ensuite la représentation à la taille cible tout en gardant une trace des informations les plus importantes qui seront utilisées plus tard pour reconstruire le signal d’origine. (Ce signal compressé est ce qui est envoyé via un réseau ou enregistré sur le disque.) Enfin, le décodeur transforme les données compressées en audio en temps réel à l’aide d’un réseau neuronal sur un seul processeur.
Publicité
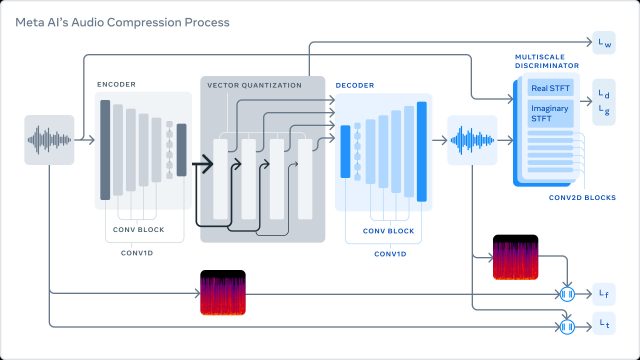 Agrandir / Un schéma fonctionnel illustrant le fonctionnement de la compression EnCodec de Meta.
Agrandir / Un schéma fonctionnel illustrant le fonctionnement de la compression EnCodec de Meta.
Méta IA
L’utilisation de discriminateurs par Meta s’avère essentielle pour créer une méthode permettant de compresser autant que possible l’audio sans perdre les éléments clés d’un signal qui le rendent distinctif et reconnaissable :
“La clé de la compression avec perte est d’identifier les changements qui ne seront pas perceptibles par les humains, car une reconstruction parfaite est impossible à bas débit. Pour ce faire, nous utilisons des discriminateurs pour améliorer la qualité perceptuelle des échantillons générés. Cela crée un cat- et-jeu de souris où le travail du discriminateur est de faire la différence entre les échantillons réels et les échantillons reconstruits. Le modèle de compression tente de générer des échantillons pour tromper les discriminateurs en poussant les échantillons reconstruits pour qu’ils soient plus perceptuellement similaires aux échantillons originaux.
Il convient de noter que l’utilisation d’un réseau neuronal pour la compression et la décompression audio est loin d’être nouvelle, en particulier pour la compression de la parole, mais les chercheurs de Meta affirment qu’ils sont le premier groupe à appliquer la technologie à l’audio stéréo 48 kHz (légèrement meilleur que le taux d’échantillonnage de 44,1 kHz du CD ), ce qui est typique pour les fichiers musicaux distribués sur Internet.
En ce qui concerne les applications, Meta affirme que cette “hypercompression de l’audio” alimentée par l’IA pourrait prendre en charge “des appels plus rapides et de meilleure qualité” dans de mauvaises conditions de réseau. Et, bien sûr, étant Meta, les chercheurs mentionnent également les implications métavers d’EnCodec, affirmant que la technologie pourrait éventuellement offrir “des expériences métavers riches sans nécessiter d’améliorations majeures de la bande passante”.
Au-delà de cela, nous obtiendrons peut-être un jour de très petits fichiers audio musicaux. Pour l’instant, la nouvelle technologie de Meta reste en phase de recherche, mais elle pointe vers un avenir où l’audio de haute qualité peut utiliser moins de bande passante, ce qui serait une excellente nouvelle pour les fournisseurs de haut débit mobile avec des réseaux surchargés de médias en continu.