

{kind=link}
Agrandir / Une image générée par l’IA de la silhouette d’une personne.
Ars Technica
Jeudi, les chercheurs de Microsoft ont annoncé un nouveau modèle d’IA de synthèse vocale appelé VALL-E qui peut simuler de près la voix d’une personne lorsqu’on lui donne un échantillon audio de trois secondes. Une fois qu’il a appris une voix spécifique, VALL-E peut synthétiser l’audio de cette personne disant n’importe quoi et le faire d’une manière qui tente de préserver le ton émotionnel de l’orateur.
Ses créateurs pensent que VALL-E pourrait être utilisé pour des applications de synthèse vocale de haute qualité, l’édition de la parole où un enregistrement d’une personne pourrait être édité et modifié à partir d’une transcription textuelle (en lui faisant dire quelque chose qu’il n’a pas fait à l’origine), et la création de contenu audio lorsqu’il est combiné avec d’autres modèles d’IA génératifs comme GPT-3.
Microsoft appelle VALL-E un “modèle de langage de codec neuronal”, et il s’appuie sur une technologie appelée EnCodec, que Meta a annoncée en octobre 2022. Contrairement à d’autres méthodes de synthèse vocale qui synthétisent généralement la parole en manipulant des formes d’onde, VALL-E génère codes de codec audio discrets à partir d’invites textuelles et acoustiques. Il analyse essentiellement le son d’une personne, décompose ces informations en composants discrets (appelés “jetons”) grâce à EnCodec, et utilise des données d’entraînement pour faire correspondre ce qu’il “sait” sur la façon dont cette voix sonnerait si elle prononçait d’autres phrases en dehors des trois -deuxième échantillon. Ou, comme le dit Microsoft dans l’article VALL-E :
Pour synthétiser la parole personnalisée (par exemple, zéro-shot TTS), VALL-E génère les jetons acoustiques correspondants conditionnés sur les jetons acoustiques de l’enregistrement inscrit de 3 secondes et l’invite de phonème, qui contraignent respectivement le locuteur et les informations de contenu. Enfin, les jetons acoustiques générés sont utilisés pour synthétiser la forme d’onde finale avec le décodeur de codec neuronal correspondant.
Microsoft a formé les capacités de synthèse vocale de VALL-E sur une bibliothèque audio, assemblée par Meta, appelée LibriLight. Il contient 60 000 heures de discours en anglais de plus de 7 000 locuteurs, principalement extraits des livres audio du domaine public LibriVox. Pour que VALL-E génère un bon résultat, la voix dans l’échantillon de trois secondes doit correspondre étroitement à une voix dans les données d’apprentissage.
Publicité
Sur le site Web d’exemple VALL-E, Microsoft fournit des dizaines d’exemples audio du modèle d’IA en action. Parmi les échantillons, le “Speaker Prompt” est l’audio de trois secondes fourni à VALL-E qu’il doit imiter. La “Ground Truth” est un enregistrement préexistant de ce même locuteur prononçant une phrase particulière à des fins de comparaison (un peu comme le “contrôle” dans l’expérience). La “Baseline” est un exemple de synthèse fournie par un procédé de synthèse texte-parole conventionnel, et l’échantillon “VALL-E” est la sortie du modèle VALL-E.
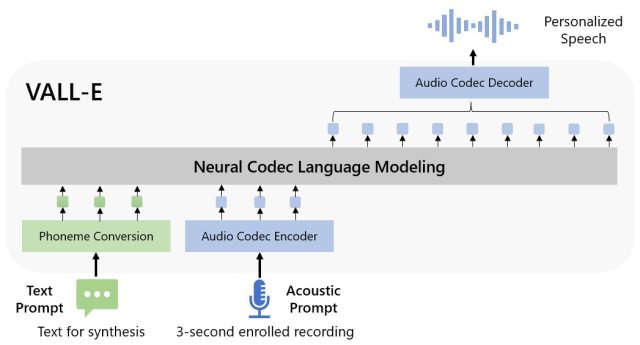 Agrandir / Un schéma fonctionnel de VALL-E fourni par les chercheurs de Microsoft.
Agrandir / Un schéma fonctionnel de VALL-E fourni par les chercheurs de Microsoft.
Microsoft
Tout en utilisant VALL-E pour générer ces résultats, les chercheurs n’ont introduit que l’échantillon “Speaker Prompt” de trois secondes et une chaîne de texte (ce qu’ils voulaient que la voix dise) dans VALL-E. Comparez donc l’échantillon “Ground Truth” à l’échantillon “VALL-E”. Dans certains cas, les deux échantillons sont très proches. Certains résultats VALL-E semblent générés par ordinateur, mais d’autres pourraient potentiellement être confondus avec le discours d’un humain, ce qui est l’objectif du modèle.
En plus de préserver le timbre vocal et le ton émotionnel d’un locuteur, VALL-E peut également imiter “l’environnement acoustique” de l’échantillon audio. Par exemple, si l’échantillon provient d’un appel téléphonique, la sortie audio simulera les propriétés acoustiques et fréquentielles d’un appel téléphonique dans sa sortie synthétisée (c’est une façon élégante de dire que cela ressemblera également à un appel téléphonique). Et les exemples de Microsoft (dans la section “Synthèse de la diversité”) démontrent que VALL-E peut générer des variations dans le ton de la voix en modifiant la graine aléatoire utilisée dans le processus de génération.
Peut-être en raison de la capacité de VALL-E à potentiellement alimenter les méfaits et la tromperie, Microsoft n’a pas fourni de code VALL-E pour que d’autres puissent l’expérimenter, nous n’avons donc pas pu tester les capacités de VALL-E. Les chercheurs semblent conscients des dommages sociaux potentiels que cette technologie pourrait apporter. Pour la conclusion de l’article, ils écrivent:
“Étant donné que VALL-E pourrait synthétiser la parole qui maintient l’identité du locuteur, il peut comporter des risques potentiels d’utilisation abusive du modèle, tels que l’usurpation d’identité vocale ou l’usurpation d’identité d’un locuteur spécifique. Pour atténuer ces risques, il est possible de construire un modèle de détection pour discriminer si un clip audio a été synthétisé par VALL-E. Nous mettrons également en pratique les principes de Microsoft AI lors du développement ultérieur des modèles.