

{kind=link}
As Shakespeare would have it, “that which we call a rose by any other name would smell just as sweet.” But in the world of computers, that way by which we represent a number in hardware can mean the difference between a blazing fast machine or a costly $475 million bug — Pentium 4 anyone?
Welcome to arguably the most fundamental component of computer design: how numbers are represented in hardware! We all know that modern computers operate on binary numbers and are extremely efficient at doing so. But this was not always the case. And what’s more, many tech giants today, including Microsoft, Nvidia, Intel, Arm, and Tesla are all revisiting how they encode numbers in hardware, in order to squeeze out every last bit of performance.
But we are getting a little ahead of ourselves. In this article, we will take a look at how this all came to be. From the early inception of binary numbers to the modern world of floating point, this seemingly simple concept can become quite complex, so let’s start from the beginning…
From Natural Numbers to Binary Numbers
When we first learn about numbers in grade school, we typically begin with natural numbers (1, 2, 3, 4…). Natural numbers are used in all sorts of day-to-day situations, from counting items to monetary transactions, and a multitude of ways in-between. Eventually, we learn about the concept of zero, and over time get introduced to more advanced concepts such as negative numbers, complex numbers, and algebraic variables.
The ability to perform computations on numbers expands their utility beyond just counting things. Simple transaction-based computations use addition and subtraction; multiplication and division can be leveraged to speed up the basic computational arithmetic; and eventually complex equations and algorithms can help solve unknowns.
Basic numbers and mathematics might be easy for a human to wrap their mind around, but how would a machine do all of this, and, potentially, do it even faster than a human? Well, this was precisely the question Gottried Lebniz would spend his life trying to answer, back in the 1600s.
A Historical Walkthrough: The Invention of Binary
Leibniz (1646-1716) was a German polymath, active in law, philosophy, mathematics, languages, science, and theology. In the mathematics field, he is most famous for his independent invention of calculus alongside Isaac Newton. His invention of binary arithmetics and hexadecimal notation would go unnoticed for centuries, until it eventually led to the foundation of today’s world of digital computing and communication.

When he wasn’t inventing calculus or consumed with his many intellectual endeavors, Leibniz was consumed with finding a way to perform computations quickly. He did not want to “waste” time performing “simple” operations such as addition and subtraction, and was convinced that there must be a way to distill information into a very basic form for quick math.
A deeply religious man living in the Holy Roman Empire, Leibniz believed that numbers and math were divinely inspired, and was set on finding a way to connect the two. He first developed a number system in 1679 in a manuscript called, “On the Binary Progression” to represent numbers using just 0s and 1s. While he was able to represent numbers in a “simple” manner using binary notation, he found binary calculations to be “longer, albeit easier.” Fast-forward to the 20th century, and this would actually become the fundamental tenant for binary computers.
Binary Primer
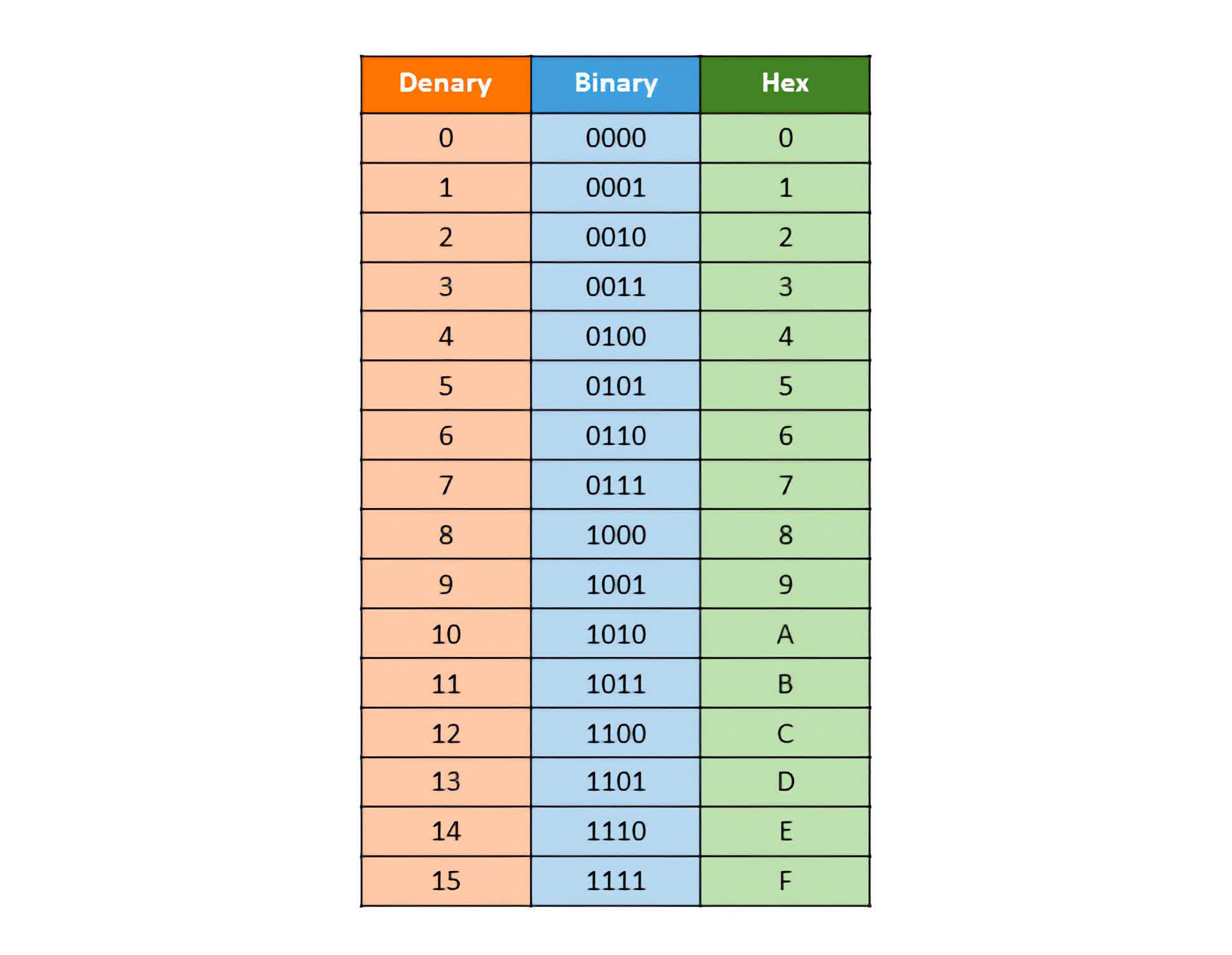
Technically speaking, Leibniz came up with a way to represent any decimal number (that is, a base 10 number, which humans typically use) as a binary number (base 2), where each bit represents a power of two.
For example, the decimal number 5 can be represented in binary as 101, with the rightmost bit representing 2^0 (= 1), the middle bit representing 2^1 (= 2), and the leftmost bit representing 2^2 (= 4).
| Decimal | Binary |
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0010 |
| 3 | 0011 |
| 4 | 0100 |
| 5 | 0101 |
| 6 | 0110 |
| 7 | 0111 |
| 8 | 1000 |
| 9 | 1001 |
| 10 | 1010 |
| 11 | 1011 |
| 12 | 1100 |
| 13 | 1101 |
| 14 | 1110 |
| 15 | 1111 |
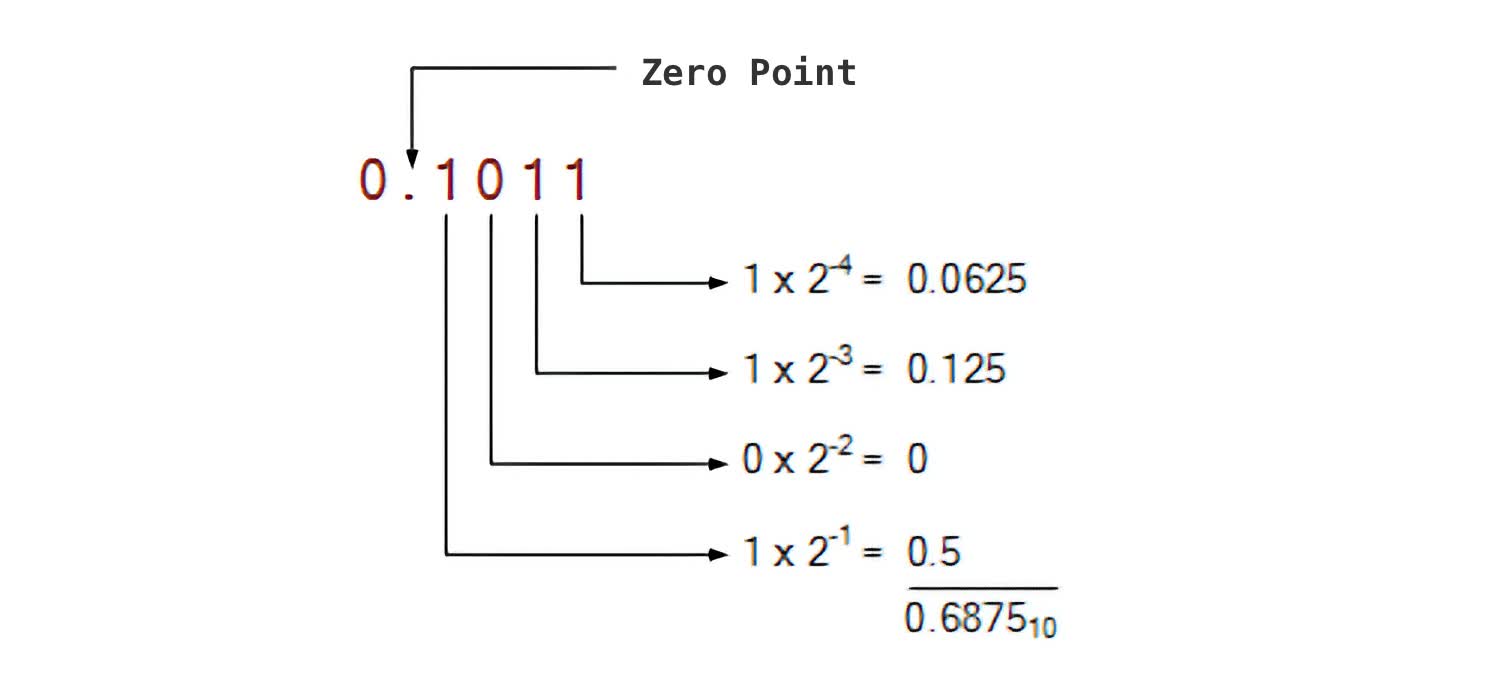
Using this formulation, you can represent any decimal number, as the table above shows. Furthermore, you can introduce a binary point (can’t just call them decimal points now, can we?) and represent fractions. Mathematically, this would be akin to raising to negative exponent values. The decimal number 0.6875 can be represented in binary as 0.1011, with the rightmost bit in the case representing 2^-4 (= 0.0625).
Leibniz revisited binary numbers about 20 years later, in 1697, during a discussion with Duke Rudolph of Brunswick and Luneburg, who made the connection between binary numbers and the concept of creation ex nihilo, according to which all things were created from nothing by the one God. Excited by the revelation (in addition to even more “proof” of divine representation of numbers from Christian missionaries in China learning about Yin and Yang’s binary nature), Leibniz was consumed the rest of his life working to convince the public about his discovery.
Although his theological connection never took hold with public opinion, he did release many manuscripts on interesting phenomena when using binary to represent natural numbers.
For example, Leibniz noted an interesting property of geometric progression (e.g., 1, 2, 4, 8, 16, 32, …) that was at the heart of binary numeration, namely, that the sum of any three consecutive terms is always divisible by 7. This, along with a multitude of “random” discoveries that Leibniz came across, helped convince him about the importance of binary representation, but it never actually took off as a way to do real math until the 20th century and the digital revolution stumbled upon it.
From Binary to Hexadecimal Numbers
During these years, Leibniz also thought about other number formats such as base 12 and 16, in an effort to address the “longer, albeit easier” nature of binary, mathematically. His discovery of hexadecimal was the first to introduce the letters a, b, c, d, e, and f to represent 10, 11, 12, 13, 14, and 15, which we today see in many applications.
As a quick primer, our “natural” way of using numbers in everyday interactions uses base 10. This essentially means that we have 10 symbols (0, 1, 2, …, 8, and 9), and once we run out of symbols, we reuse the symbols in the next “place” to keep counting. With this methodology, we can encode any arbitrary value using our set of predetermined symbols.
In the binary system, there exists only two symbols: 0 and 1. Otherwise, the methodology holds the same to the decimal system: 0 is encoded as 0, 1 is encoded as 1, and then 2 is encoded as 10 (since we “ran out” of symbols). As Leibniz said, this is technically very simple, but will result in more “digits” for numbers. But, looking ahead to the invention of the transistor in the 20th century, the binary system naturally lends itself to the on/off nature of a switch.
While the conversion of numbers between decimal and binary isn’t too complex, performing computations in binary (for a human) can get a bit unwieldy and is error-prone, given the many digits of the encoding format. An entire field intersecting between math and computer science was created to better grasp the nature of computing with zeros and ones.
Boolean Algebra and Information Theory
While Leibniz might have introduced the notion of binary numbers, George Boole (after which Boolean Algebra is named) went about formalizing how computations can be performed using just 0s and 1s. Think of this as the “discovery” of how to do long multiplication (for efficiency) after learning about repeated addition, allowing generalization and scalability of binary numbers.
In 1847, Boole published a paper called, “The Mathematical Analysis of Logic,” describing how an ON-OFF approach can form the three most basic operations in digital logic: AND, OR, and NOT. With just these three operations, Boolean operators allow for a foundation to use binary to process information. Today, we find these three operators everywhere inside our digital machines, essentially forming the Arithmetic Logical Unit (ALU) in modern day processors and many instructions of an Instruction Set Architecture (ISA).
While this is all great, one of the fundamental limitations of binary numbers is how much information can they represent?
Let’s explain this by example: if we have a single bit, representing 0 or 1, we can encode a total of 2 different things. That is, we can map the value of “0” to represent a unique object, and map the value of “1” for another object. Increasing the number of bits to 2, and we now have a combination of 00, 01, 10, and 11, or a total of 2^2 = 4 things that can be represented.
This pattern continues exponentially: if you have 8 bits (or a byte), you can represent up to 2^8 = 256 unique things. And of course, with 32 bits, you can represent up to 4,294,967,296 unique things.
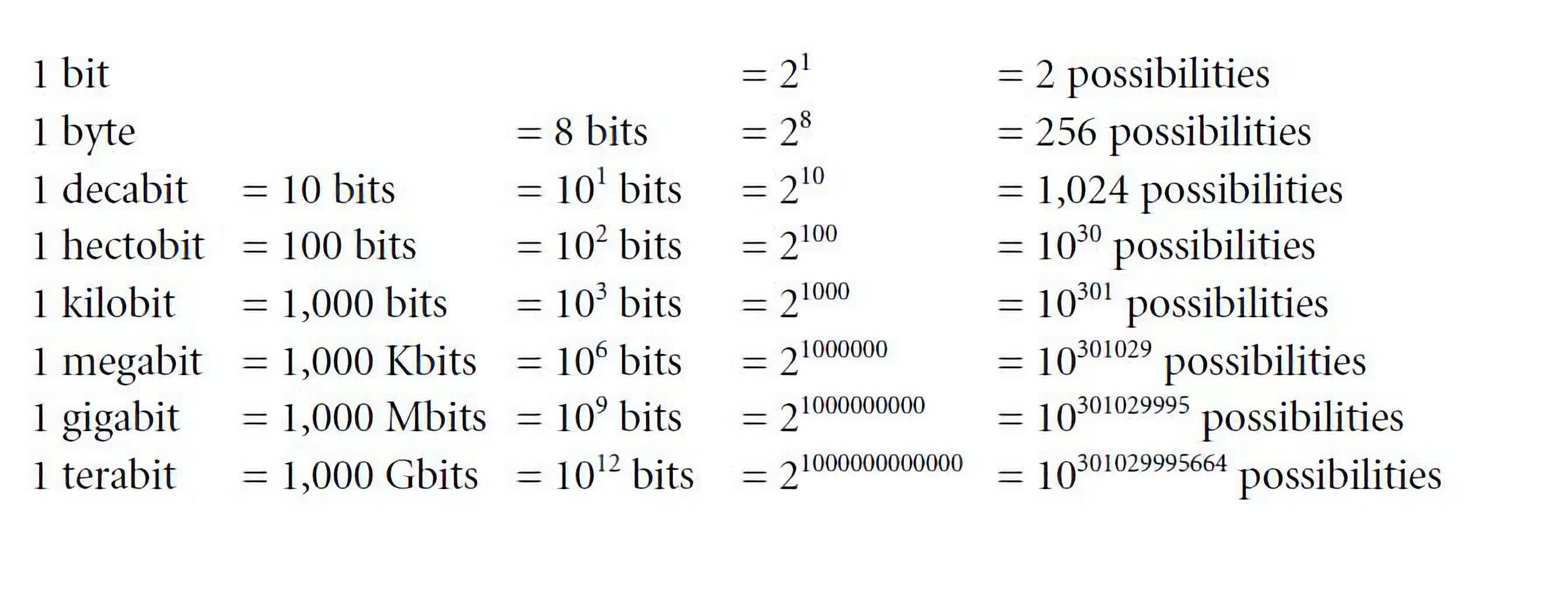
What are these “things”? Well, in the field of numerics, it means you can “only” represent a little above 4 billion unique numbers with 32 bits. This limitation turns into a hardware problem, since numbers are fundamentally limitless and infinite.
Thus, how do you go about representing an infinite set of numbers (including integers, fractions, negatives, and perhaps “special” numbers like infinity) efficiently in hardware? Herein lies the fundamental idea behind hardware number representations.
The “Problem” with Numbers: 1970-1985
Numbers are infinite in nature. Mathematically speaking, this means that it is impossible to represent in hardware every single number from the largest exponents to the smallest decimals. Thus, an essential question a processor designer needs to grapple with is, “Which numbers can/should the hardware support?”
From an information theory perspective, the closely related question of, “How many numbers can be represented?” is tied to the number of bits available. This is a practical question that can be answered by the designer, especially during the early microprocessor days when resources were at a premium.
Going back to our example above: suppose you choose to represent numbers using 8 bits. That means you can represent up to 2^8 unique numbers, or 256 numbers. Which two-hundred and fifty-six number you choose to represent is a different question.
- Do you support just the positive integers, 0 to 255?
- Do you support both positive and negative integers centered around zero: -128 to +127.
- Or do you care about decimal numbers? For instance, you can choose to support 256 fractional values uniformly between 0 and 1: (0/256, 1/256, 2/256, … , 255/256).
Furthermore, what do you do with the end points? In the last example, do you choose to represent 0 or 1? You don’t have enough bits to represent both! With 8-bits, you can represent up to 256 unique values from 0000 0000 to 1111 1111. If you start mapping them at 0 (for 0000 0000), then you can only go up to 255/256 = 0.99609375, and you have no spare representations for the value “1”!
Another challenge is how do you handle “weird” situations, such as division by zero? In the hardware, do you want that to be represented as “infinity”? Or maybe reserve a bit representation for “Not-a-Number (NaN)”? Which unique bit sequence do you set aside for these “denormals”?
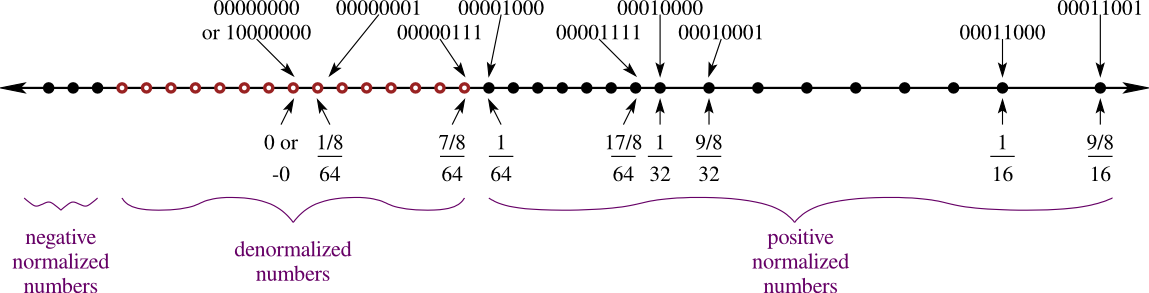
Welcome to the world of digital representation of numbers, where you are given a fixed budget of bits (e.g., 8, 16, or 32) and are tasked with encoding numbers efficiently. To complicate matters further, in a general purpose processor you have no idea what application will be running on this hardware, and need to handle all exceptions and values gracefully. What do you do?
In the 1970s and early 1980s, this led to the wild west of number formats. More than 50 different number representations were implemented in hardware designs, with various design decisions based on the manufacturers’ goals and needs.
This caused a real problem: two computers can be performing the same mathematical operation (e.g., add, sub, mul, div), but produce different results! This was especially egregious in scientific computing applications, where computational drift in values means that small errors eventually compounded to huge differences.
The IEEE-754 floating point standard was established in 1985 to address this. Specifically, code portability helped usher in the adoption of this standard. Today, as long as two computers are IEEE-754 compliant, then the same mathematical operation is guaranteed to result in the same outcome. (We still haven’t addressed what that outcome would be — and what approximations IEEE-754 would make standard).

Since 1985, there have been two number format refreshes (in 2008 and 2019) which address some design bugs and introduce various extensions for the standard. The details of the refreshes are way too technical, but you can check out the Wikipedia article for specifics. Here, we’ll just give an overview of the design decisions that were made for the floating point standard, and why it is called a “floating” point.
IEEE-754 Floating Point Explained
The floating point standard was officially unveiled in 1985 by the IEEE, and was the brainchild of William Kahan. Kahan won the prestigious Turing Award (the computing equivalent for a Nobel Prize) a few years later for his contributions as the “Father of Floating Point.” Accolades aside, what is Floating Point?
Unlike the concept of a fixed decimal point, the Floating Point (FP) standard introduced a systematic way of re-interpreting 32 bits by allowing the “point” between the whole part of a number and the fractional part of a number to change. Analogously, it can be thought of as scientific notations, but with a constraint on which numbers are representable in hardware. The fundamental tradeoff and difference between a fixed point format and a floating point format is the range and precision of the numbers being represented.

Let’s walk through this.
Fixed Point Representation
Recall from the information theory primer above that with 32 bits, we can represent exactly 2^32 = 4,294,967,296 unique numbers. A fixed-point format, which is the traditional way of encoding numbers in binary as envisioned by Leibniz, can represent only a certain set of values depending on where the decimal place is pegged.
For example, let’s assume we allocate 1 sign bit, 15 integer bits, and 16 fractional bits (shorthand as (1, 15, 16) ) as follows:

With this representation, the largest number we can encode is 32767.99998474121, and the smallest number we can encode is -32768. Additionally, there are certain numbers within this range that are not representable. For example, if we want to encode 21845.33333333, we find that 32 bits does not allow for that. If we wanted to use this number on a machine with a fixed point (1, 15, 16) scheme, we would have to round it to something — for example, the fractional part would be represented with .3333282470703125 as the closest “legal” value. And during the Wild West of number formats, it really was up to the hardware designer to figure out how and when to round.
One solution is that we can move the decimal point and change our implementation, perhaps to a (1, 7, 24), or 1 sign bit, 7 integer bits, and 24 fractional bits. But that creates a new problem: by increasing our precision, we had to reduce the range of numbers that can be represented. With a (1, 7, 24) allocation of bits, our range now only goes from 127.99999994039536 to -128. The value of 21845 is not even close to being represented!
This was fundamentally the problem with using fixed point numerical representations, and before the 1985 standard, every hardware vendor would basically choose whatever range and precision they deemed useful for their applications. Throw in the issue of rounding, too, and we can be certain that not all 32-bit implementations of numbers are the same.
Floating Point Representation
Rather than sticking to a basic binary representation, the Floating Point standard chose an alternative hardware data structure to get around this issue. Instead of allocating 32 bits into integer and fraction parts (which is intuitive to humans), the FP standard uses an exponent and mantissa region for encoding numbers.
To pull this off, additional hardware is required to reinterpret the 32 bits, as shown below. One bit is reserved for the sign (+1 or -1), 8 bits are allocated for the exponent, and 23 bits are used for the mantissa. Then, you can simply plug the values into the following formula (where the bias is set to 127), and get a value from the 32-bits of 0s and 1s.
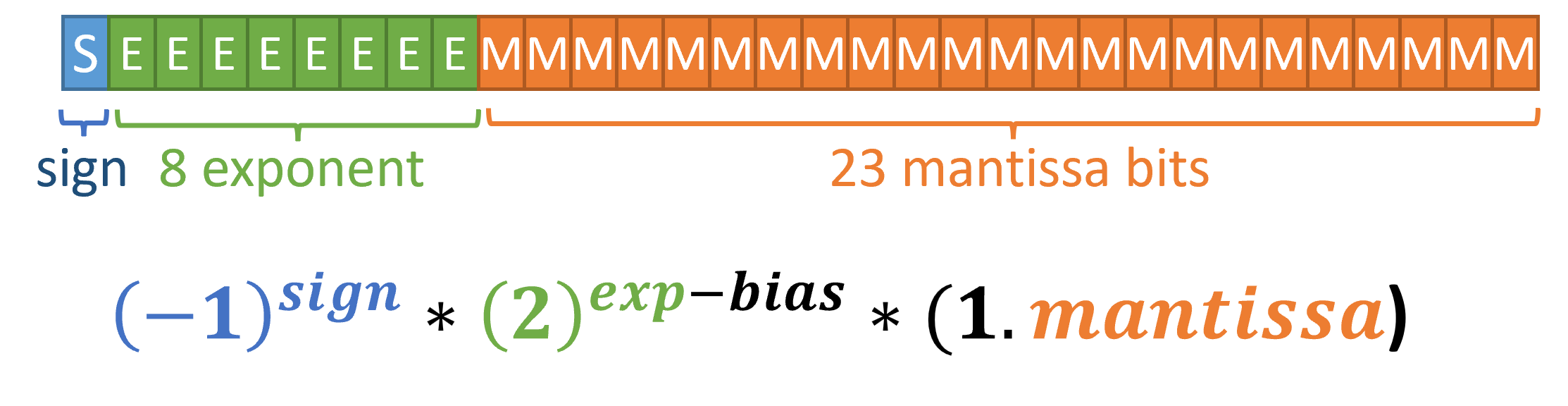
The idea is that you can now represent numbers across large and small orders of magnitude via the exponent, and then have enough bits (the mantissa) for high resolution at those particular magnitudes. The floating point (to generalize beyond the decimal or binary point) would adjust to the magnitude of certain numbers using exponentiation, and the mantissa can focus in on the desired number in that region.
Recall the discussion about precision versus range? Here is where it shows up: in the IEEE-754 standard, numbers near zero have much more precision than numbers further away from zero. That said, you can still represent very large and very small numbers (i.e., a large range) since you have 2^8 or 256 different representable exponent values (well, not exactly 256, but we’re coming to that).

An IEEE-754 Floating Point Example
Let’s put this all together! How would we represent 5 in IEEE-754?
The sign bit is 0, since this is a positive number. For the exponent region, we need to get to the closest power of 2, which is 4, or 2^(2). Since there is an implicit bias of 127 in the formula, we need our exponent to be 129, or 10000001. With that, 129 – 127 = 2.
Finally, we need 2^(2) x mantissa to equal 5, so the mantissa needs to encode 5/4 or 1.25. The 1 is implied, leaving us with 010 0000 0000 0000 0000 0000. Our final 32 bit representation is 0100 0000 1010 0000 0000 0000 0000 0000.
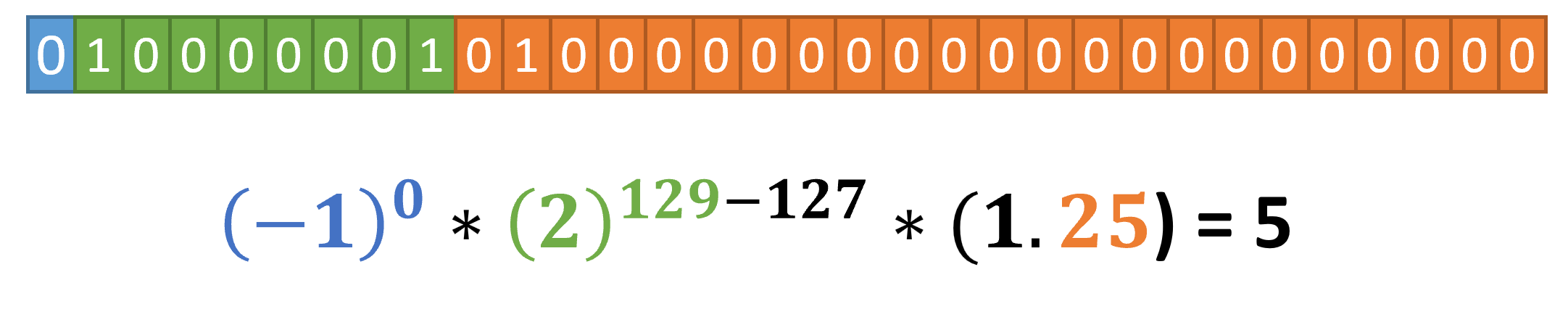
That’s it!
Ok, well, that wasn’t as straightforward as someone would assume. But, like Leibniz suggested more than 400 years ago, this is pretty easy for a computer to do, and now we can represent way more numbers with 32 bits than previously possible with a fixed-point scheme.
To save you some time, here is a handy calculator to play around with floating point numbers.
Special values in IEEE-754 Floating Point
Although the exponent technically allows up to 2^8 or 256 different representations, there are a couple of special numbers reserved for “other” numbers. Specifically, if all the bits are set to 1 (e.g., 1111 1111), then this special number represents infinity if all the mantissa bits are set to 0. If the mantissa bits are anything other than zero, then the bit representation encodes “NaN”, or “Not a Number”. This is commonly used as a way for signaling certain errors in hardware, where unexpected computations (such as divide-by-zero) can be identified when an infinity or NaN pop up.
Similarly, if all values are 0 (e.g., 0000 0000), then the mantissa bits are interpreted as subnormal numbers. In most floating-point number representations, normal numbers are represented with a non-zero mantissa and an exponent that falls within a specific range. In contrast, subnormal numbers have a mantissa that is not normalized, meaning that the leading bit of the mantissa is zero, and the exponent is set to the minimum representable value. This allows subnormal numbers to represent very small values with limited precision.
IEEE-754 Floating Point Standard takes hold: 1985-2012
Following the introduction of the standard, the computing industry almost universally adopted IEEE-754 as the number format representation for hardware. No major changes or newsworthy designs occurred during these years.
Probably the most notable number-format related news item was the 1994 Intel floating point division bug, which cost the company nearly half-a-billion dollars to address. This was an implementation issue in the Pentium processor. Although Intel claimed IEEE-754 compliance, a faulty design led to computational error in the division operation, which (as mentioned earlier) caused computational drift issues.
Besides that, many jokes and memes among computer science practitioners arose during this time. Despite being a standard, it was/is still difficult to comprehend that a mathematical operation can have different results than what a human would expect, yet the hardware can still be totally compliant under the standard (!).
However, in the last decade, the standardization of number formats hit a road bump. The rise of deep learning as a resurgent application domain led to the rethinking of how numbers should be represented in hardware.
Deep Learning and Number Formats: 2012 – Present
Few people dabbled with the IEEE-754 standard for nearly 30 years. And why would they: it had solved one of the biggest problems with early computing: portability. That is, any processor that was IEEE-754 compliant and implemented correctly should have the same numerical results from one computer to the next. This allowed for easier packaging of applications and maintained a semblance of consistency in machines worldwide.
That changed roughly around the year 2012, when deep neural networks (DNNs) took the world by a storm. In particular, a graduate student at the University of Toronto named Alex Krizhevsky used his gaming Nvidia GPU to accelerate neural network training, and won the ImageNet image classification challenge. Since then, companies have been scrambling to adopt artificial intelligence in a myriad of applications, and hardware companies in particular were interested in maximizing the performance of DNNs.
In particular, companies such as Nvidia, AMD, Intel, and Google began rethinking how numbers should be represented in hardware. The insight being that if there is information about the application running on the hardware, you can optimize the hardware significantly rather than relying on general purpose processors. And one particular hardware optimization is changing the precision and range of numbers for DNNs.
As it turns out, DNNs don’t need a full 32 bits to represent the typical values observed during training or inference. Further, rounding was typically acceptable to some degree (as long as values didn’t collapse to zero during DNN training). A logical optimization then is to reduce the number of exponent bits and mantissa bits. Luckily, there already exists such an optimization in the IEEE-754 standard, called Half Float.
A Half Float is exactly that: 16 bits instead of 32 bits. Further, the allocation of exponent and mantissa is also reduced: the exponent bits go down to 5 and the mantissa bits go down to 10.
This straightforward optimization can typically double your performance, since now fewer bits are required for computation, and few bits have to be shuffled around to and from memory.
From an application perspective though, fewer bits did reduce the DNN accuracy. For certain application domains that are safety-critical, such as self-driving cars, that accuracy reduction might not be worth the better performance. What else could be done?
Well, who said the 16 bits needed to follow the IEEE-754 standard in a (1, 5, 10) format? And this is where companies began taking charge and reimplementing number formats, in an attempt to balance performance versus accuracy.
Floating Point Variants
Google was first. They went with a (1, 8, 7) format, putting forth more bits towards the exponent (influencing the range of numbers representable) at the expense of numerical precision. Looking at it from another angle, this format mimicks the range of full FP32, but cuts down on mantissa bits, which could be considered unnecessary for this application. Coming out of Google Brain, they aptly named this new format Brain Float, or BFloat for short.
BFloat did extremely well, especially during DNN training when values got very close 0 and needed to be represented. Other number formats soon followed from other companies, including IBM, Nvidia, and AMD.
IBM’s 16-bit format, called DeepFloat, allocates 6 bits for exponent and 9 bits for the mantissa (1, 6, 9). Nvidia went with an interesting 20-bit format called TensorFloat32 (because it purported getting FP32 accuracy with just 20-bits), assigning 8 exponent bits and 11 mantissa bits (1, 8, 11). AMD went up a bit more, developing AMD FP24, a format with 7 exponent bits and 16 bits for the mantissa.
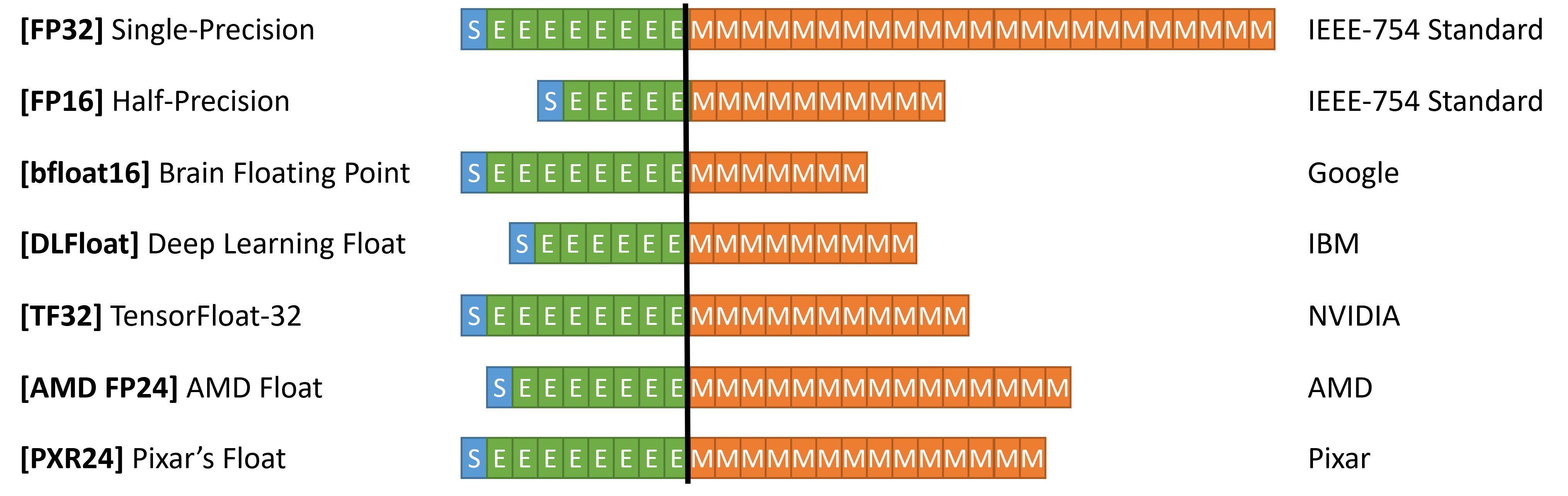
Fundamentally though, all these formats did not diverge too much from the IEEE-754 standard, in terms of how the values were interpreted. What changed was how the range and precision of the numbers were reachable, as a function of the number of exponent and mantissa bits.
In a recent attempt to “standardize” number formats across companies, Nvidia, Arm, and Intel came up with a new standard for FP8, an 8-bit number format. FP8 is a bit more interesting than the previously mentioned formats, because it is actually 2 number formats under-the-hood: a (1,5,2) configuration and a (1,4,3) configuration. The idea is that to comply with this standard, the hardware should be able to switch between and allow both number formats to work, with portability in mind.
Block Float
Why stop at just changing the meaning of numbers in hardware? What if you can make a few hardware changes to make things run even faster?
This is the path Microsoft took with Block Float. The intuition behind Block Float is that in many DNN applications, many values actually have the same exponent value, but differ in their mantissa values. Said differently, the values don’t span a large range. Thus, why not extract the exponent bits and share them across a bunch of values, and only store the mantissa bits?

The figure above illustrates how block float works. Depending on how large a block is (say 8, 16, 32 values), you can get some significant savings in storage and communication bandwidth, by shuffling fewer bits around. It does take a bit of smarts to figure out the right granularity for exponent sharing, and you might need a dedicated register (or a couple) in hardware to support multiple simultaneous blocks, but the performance benefits speak for themselves.

Surprisingly, the concept of Block Float actually came up in the 1970s, during the Wild West of number formats. Its resurgence today mostly has to do with the domain-specific hardware optimizations, targeting AI. By knowing a little something about the running program (i.e., that values typically operate in the same range of values), you can perform hardware-centric optimizations to get performance speed-ups.
AdaptivFloat
Another cool number format that recently emerged is called AdaptivFloat. This number format came from a Harvard research lab in 2020, and independently adopted by Tesla for their Dojo architecture, called CFloat.
The basic idea behind AdaptivFloat is to introduce a number format that can dynamically adapt to the values in each layer of a DNN. Values within a layer typically do not span a wide range themselves, but across layers they could differ. Thus, adapting the numerical representation in hardware to the software values efficiently would give the best of both worlds in performance (via shorter bitwidths) and accuracy (by being more faithful to numerical precision).
How does AdaptivFloat accomplish that? By adaptively changing the exponent bias in the floating point standard. Recall that in the IEEE-754 format, there is an implicit bias of 127 applied to exponent values. This comes up in the formula as well, where the exponent value represented in binary needs to be subtracted by 127, and then this value is used for the exponent.
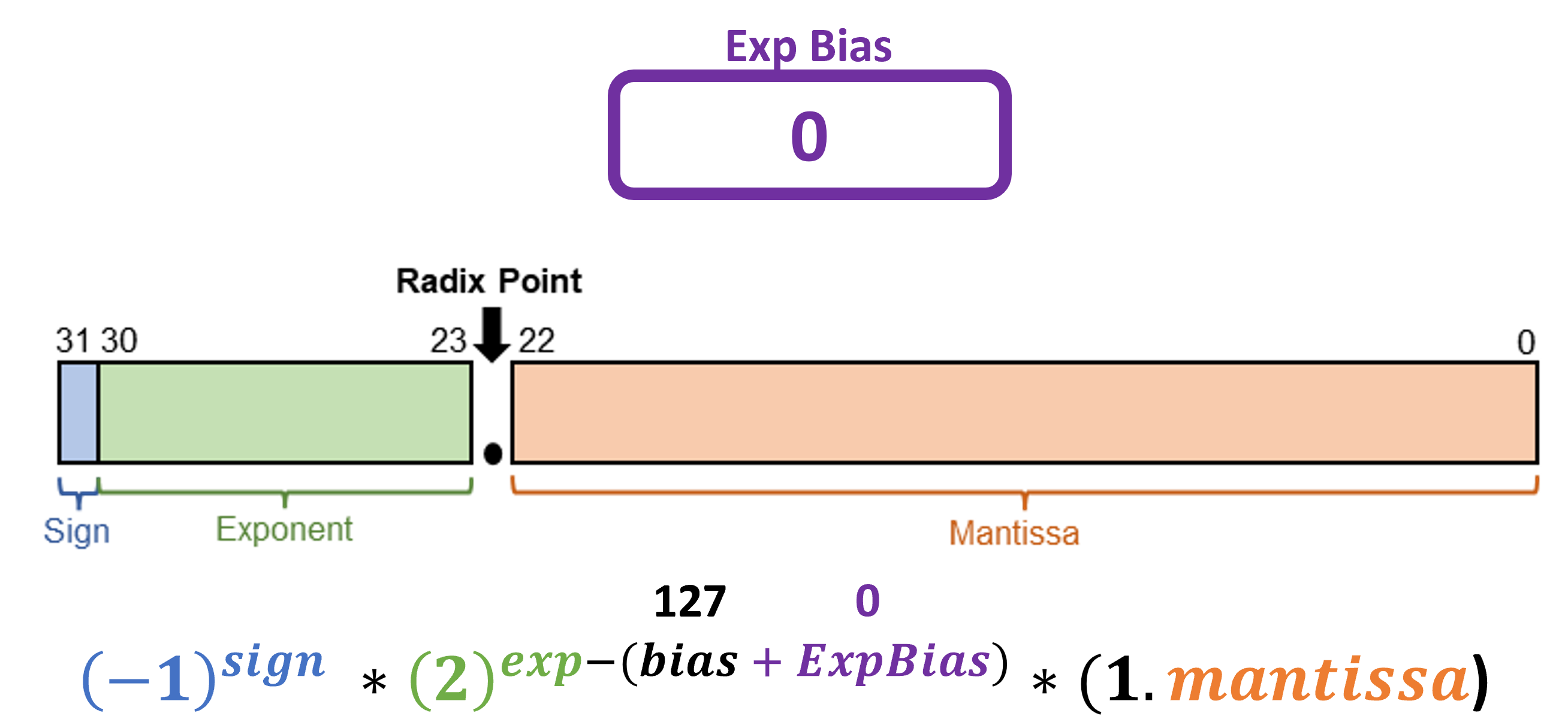
What happens if you change the implicit 127 to something like 125? You essentially move the floating point to another range of values, since the exponent changed (in the figure above, ExpBias would be -2). Intuitively, AdaptivFloat manipulates the dynamic range of values at the layer granularity, using minimal hardware overhead to change the exponent bias. Thus, by adding a simple register to offset and adapt to the numbers you want to express, you can more-or-less keep a lot of the same hardware, but play around with the dynamic range.
AdaptivFloat is a clever little hardware trick that is definitely application-inspired. By unpacking the IEEE-754 standard and altering basic assumptions (in this case, the implicit exponent bias), AdaptivFloat shows both good accuracy and performance compared to Block Float and other number formats, as explored in the research paper. Further, it can be combined with other bit allocations (as in, how many exponent and mantissa bits should be used?), resulting in various versions such as CFloat16 and CFloat8, as employed by Tesla.
Posits and Unum
The final number format we present are posits. Posits are actually not DNN-inspired, and the concept has been in development for a handful of years as a floating point alternative. Their main advantage is that they can squeeze out an even larger dynamic range compared to floating point, for a given bitwidth.

One of the key features of the posit format is its use of a “variable-length exponent” which allows for more efficient representation of small numbers and a wider dynamic range compared to fixed-point formats. Additionally, the posit format has a well-defined and rigorous mathematical foundation, making it well-suited for use in scientific and engineering applications.
Compared to the traditional FP32 standard, posits have an extra field for the regime. The regime bits are used to determine the magnitude of a number and to distinguish between different ranges of values.
In the posit format, the regime bits are used to specify the location of the most significant non-zero bit of the number, which determines the magnitude of the number. The number of regime bits used can vary depending on the specific implementation, but typically ranges from 1 to 3 bits. The value of the regime bits determines the range of the number and the position of the exponent field in the overall encoding.
The regime bits are an important part of the posit format, as they allow for more efficient representation of small numbers and a wider dynamic range compared to traditional fixed-point formats. They also play a crucial role in the accuracy and performance of arithmetic operations performed in the posit format.
Posits show immense potential, especially in scientific computing applications. They have yet to fully take off in hardware though, mostly because something seismic would need to happen to convince vendors to move away from the IEEE standard. Nevertheless, it presents an alternative to floating point, and many hardware companies are keeping it in their radar.
Future Implications
Who would have thought that number representations in hardware could be so diverse and be revisited by major players in industry these days? The AI revolution certainly deserves a lot of credit for this recent shift, but also the diminishing returns of Moore’s law and Dennard’s scaling which require more architectural ingenuity to squeeze out more performance out of the hardware.
Beyond runtime performance and DNN accuracy improvements, another important consideration that has recently come up is the reliability of new number formats in the context of single-bit upsets. Google and Meta have recently made calls to action from hardware companies to look into random failures in their datacenters, originating from manufacturing and transient bit flips. With so many new number formats being introduced, it does call into question which bits are the most vulnerable, and whether certain number formats (such as AdaptivFloat) are more robust to the impact of bit flips because of their implementation.
The impact on code portability will also be interesting to follow. The whole point of IEEE-754 was to formalize and standardize what to expect when a piece of code was run on different hardware devices. With AI, the claim is that there exists some fuzziness in computations which can be exploited for performance gains, and thus the rise of many reinterpretations of the standard. How will this impact future processor and accelerator design?
But besides the recent design trends for numerical number representations in hardware, it is still a marvel to see how much things have changed since Leibniz’s fascination with a “fast” way to do math. And it will be exciting to see where things take us in the next 10-15 years in this arena.
What’s in a number? Well, a lot more than what appears at face value for sure.