

{kind=link}
Agrandir / Une image générée par l’IA d’une boule de musique qui explose.
Ars Technica
Jeudi, des chercheurs de Google ont annoncé un nouveau modèle d’IA génératif appelé MusicLM qui peut créer un son musical de 24 KHz à partir de descriptions textuelles, comme “une mélodie de violon apaisante soutenue par un riff de guitare déformé”. Il peut également transformer une mélodie fredonnée en un style musical différent et produire de la musique pendant plusieurs minutes.
MusicLM utilise un modèle d’IA formé sur ce que Google appelle “un grand ensemble de données de musique sans étiquette”, ainsi que des légendes de MusicCaps, un nouvel ensemble de données composé de 5 521 paires musique-texte. MusicCaps obtient ses descriptions textuelles d’experts humains et ses clips audio correspondants de l’AudioSet de Google, une collection de plus de 2 millions de clips audio étiquetés de 10 secondes extraits de vidéos YouTube.
D’une manière générale, MusicLM fonctionne en deux parties principales : premièrement, il prend une séquence de jetons audio (morceaux de son) et les mappe à des jetons sémantiques (mots qui représentent le sens) dans les sous-titres pour la formation. La deuxième partie reçoit les sous-titres de l’utilisateur et/ou l’audio d’entrée et génère des jetons acoustiques (morceaux de son qui composent la sortie de la chanson résultante). Le système s’appuie sur un modèle d’IA antérieur appelé AudioLM (introduit par Google en septembre) ainsi que sur d’autres composants tels que SoundStream et MuLan.
Google affirme que MusicLM surpasse les précédents générateurs de musique AI en termes de qualité audio et de respect des descriptions textuelles. Sur la page de démonstration MusicLM, Google fournit de nombreux exemples du modèle d’IA en action, créant de l’audio à partir de “sous-titres riches” qui décrivent la sensation de la musique, et même des voix (qui jusqu’à présent sont du charabia). Voici un exemple de légende riche qu’ils fournissent :
Chanson reggae au tempo lent et à la basse et à la batterie. Guitare électrique soutenue. Bongos aigus avec sonneries. Les voix sont détendues avec une sensation décontractée, très expressive.
Google présente également la “longue génération” de MusicLM (création de clips musicaux de cinq minutes à partir d’une simple invite), le “mode histoire” (qui prend une séquence d’invites de texte et la transforme en une série de morceaux musicaux morphing), “texte et mélodie conditionnement” (qui prend une entrée audio de bourdonnement ou de sifflement humain et la modifie pour correspondre au style présenté dans une invite), et générer de la musique qui correspond à l’ambiance des légendes d’image.
Publicité
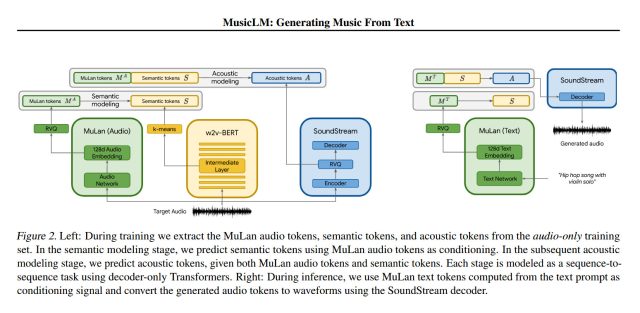 Agrandir / Un schéma fonctionnel du modèle de génération de musique MusicLM AI tiré de son article académique.
Agrandir / Un schéma fonctionnel du modèle de génération de musique MusicLM AI tiré de son article académique.
Recherche Google
Plus bas dans la page d’exemple, Google plonge dans la capacité de MusicLM à recréer des instruments particuliers (par exemple, flûte, violoncelle, guitare), différents genres musicaux, différents niveaux d’expérience de musicien, des lieux (évasion de prison, gymnase), des périodes (un club dans les années 1950), et plus encore.
La musique générée par l’IA n’est pas une idée nouvelle, mais les méthodes de génération de musique par l’IA des décennies précédentes ont souvent créé une notation musicale qui a ensuite été jouée à la main ou via un synthétiseur, tandis que MusicLM génère les fréquences audio brutes de la musique. De plus, en décembre, nous avons couvert Riffusion, un projet d’IA amateur qui peut également créer de la musique à partir de descriptions textuelles, mais pas en haute fidélité. Google fait référence à Riffusion dans son article académique MusicLM, affirmant que MusicLM le surpasse en qualité.
Dans l’article de MusicLM, ses créateurs décrivent les impacts potentiels de MusicLM, y compris le “détournement potentiel du contenu créatif” (c’est-à-dire les problèmes de droit d’auteur), les biais potentiels pour les cultures sous-représentées dans les données de formation et les problèmes potentiels d’appropriation culturelle. En conséquence, Google souligne la nécessité de travailler davantage sur la lutte contre ces risques et retient le code : “Nous n’avons pas l’intention de publier des modèles à ce stade.”
Les chercheurs de Google envisagent déjà des améliorations futures : “Les travaux futurs pourraient se concentrer sur la génération de paroles, ainsi que sur l’amélioration du conditionnement du texte et de la qualité vocale. Un autre aspect est la modélisation de la structure de chanson de haut niveau comme l’introduction, le couplet et le refrain. la musique à un taux d’échantillonnage plus élevé est un objectif supplémentaire.”
Il n’est probablement pas exagéré de suggérer que les chercheurs en IA continueront d’améliorer la technologie de génération de musique jusqu’à ce que n’importe qui puisse créer de la musique de qualité studio dans n’importe quel style simplement en le décrivant – bien que personne ne puisse encore prédire exactement quand cet objectif sera atteint ou quel impact cela aura-t-il exactement sur l’industrie de la musique. Restez connectés pour de prochains développements.